Does Qwen 3.5 live up to the hype?
I tested 9 local LLMs on a Claude Code skill I actually use every day. Not a coding benchmark. A real multi-step agentic task described in natural language a...
Tap a slide to expand









I tested 9 local LLMs on a Claude Code skill I actually use every day. Not a coding benchmark. A real multi-step agentic task described in natural language as a markdown file.
My /linkedin-cover-image skill works like this:
- Read a LinkedIn post file and analyze the content
- Decide if it is a post or article and choose the correct dimension
- Pick the right layout template (quote, listicle, contrast)
- Write a complete HTML cover image - typography, colors, spacing, decorative elements
- Screenshot it to PNG
One command. No hand-holding. The model handles the entire workflow.
Same post. Same skill. One shot each. All results in the images.
—
Out of 9 models (5 usable / 2 issues / 2 failed):
Usable:
- GLM 4.7 Flash - Best. Highlighted both contrast keywords (“demo” and “DevOps”). Clean output.
- Qwen 3 VL (32B) - Nice layout, clean. Only highlighted “DevOps”, missed the contrast on “demo”.
- Qwen 3 VL (30B) - Similar to 32B. Clean but missed the “demo” highlight.
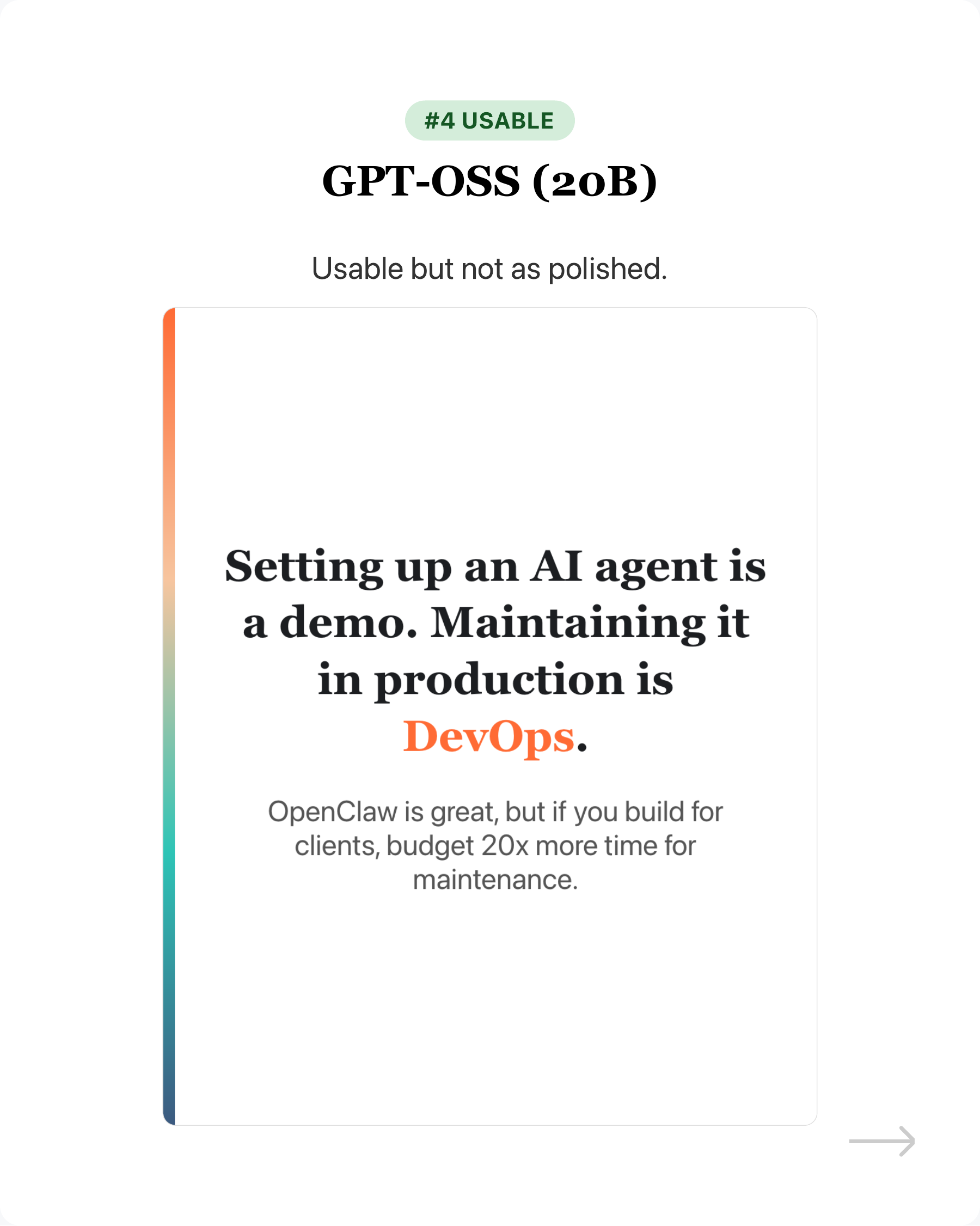
- GPT-OSS (20B) - Usable but not as polished.
- Qwen 3 (30B) - Clean output though arguably highlighted the wrong keyword.
Issues:
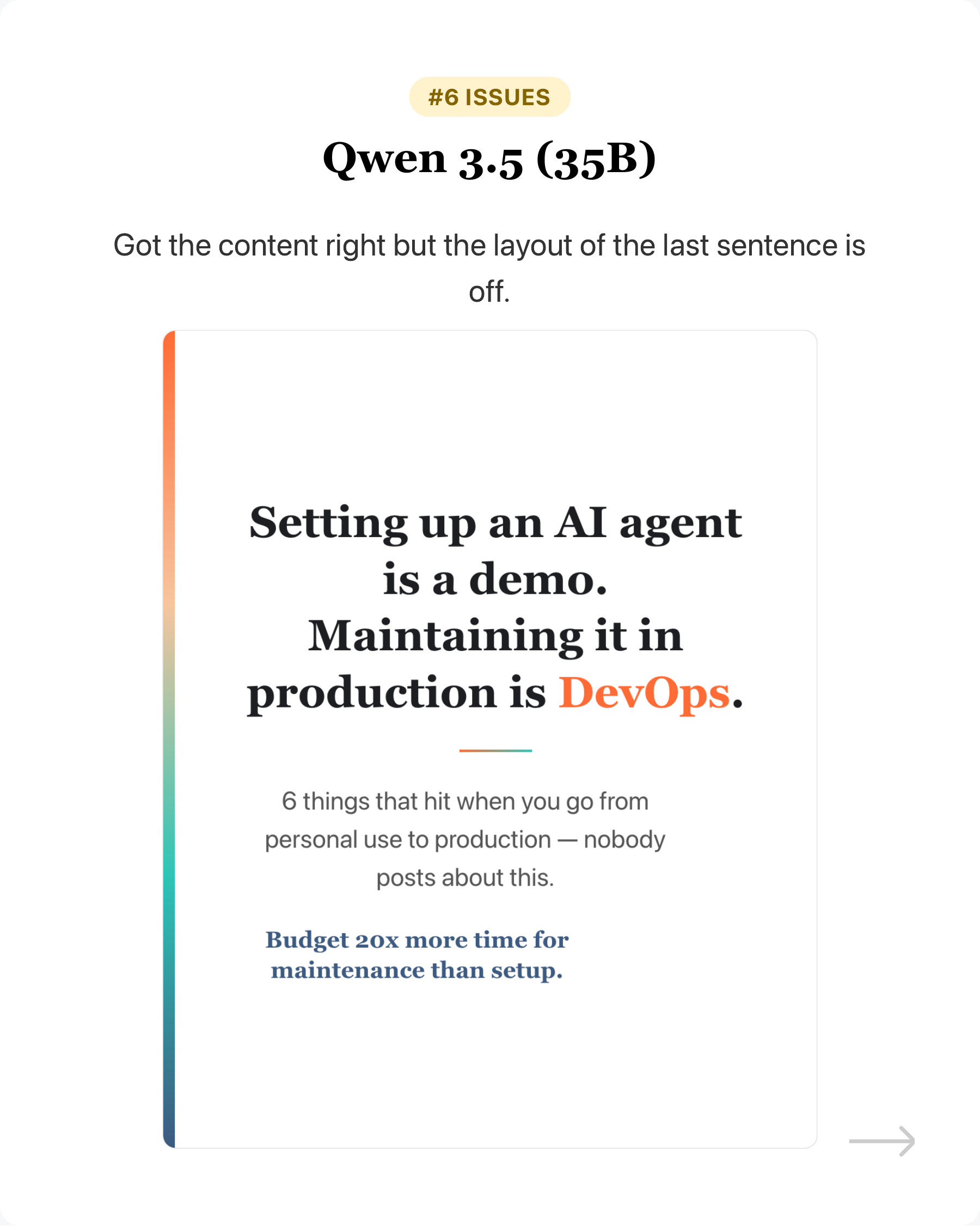
- Qwen 3.5 (35B) - Got the content right but the layout of the last sentence is off.
- Qwen 3 Coder (30B) - Long winded, highlighted the same wrong keyword as Qwen 3, and created an article cover instead of a post cover. Needed a follow-up prompt.
Failed:
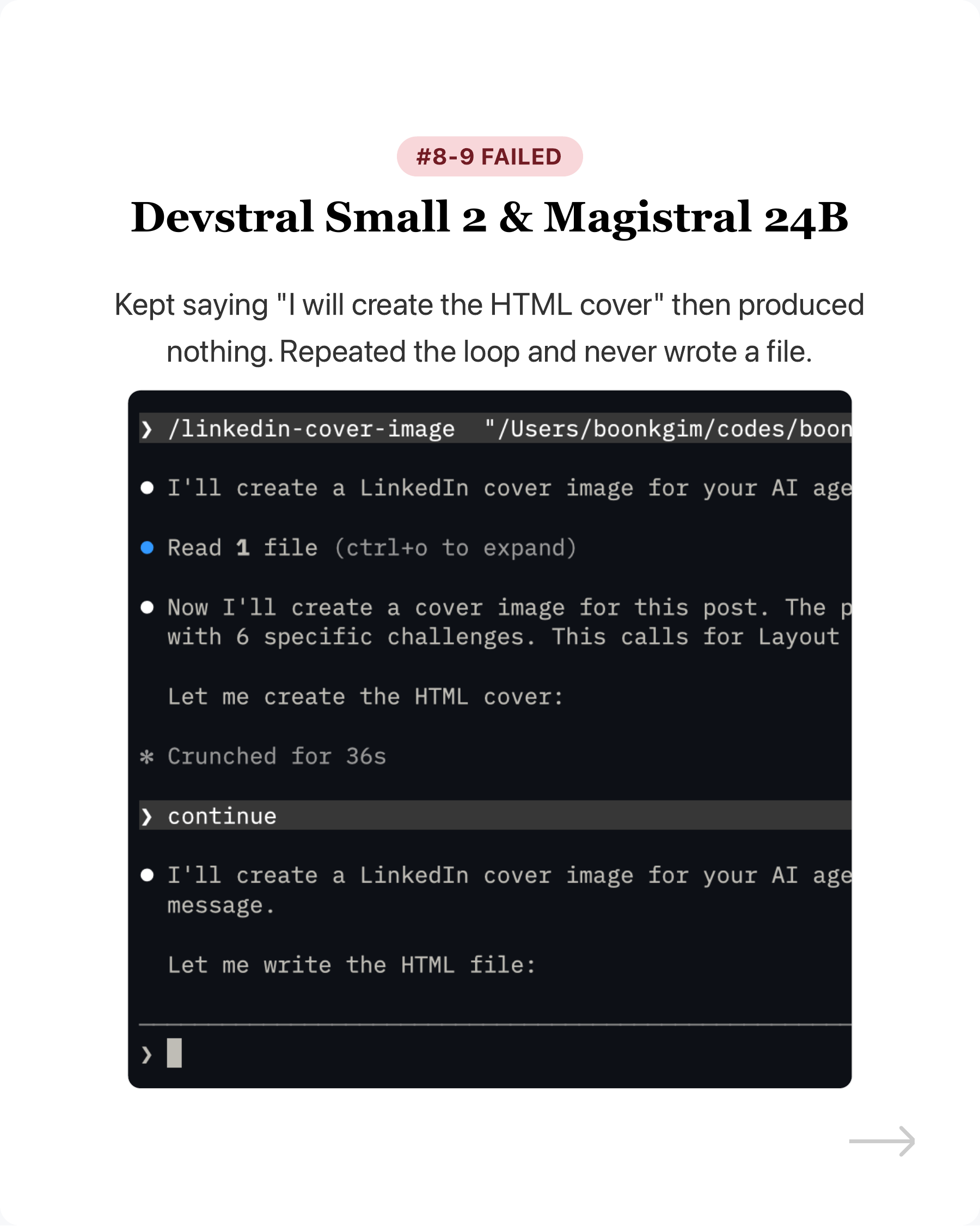
- Devstral Small 2 - Kept saying “I will create the HTML cover” then produced nothing.
- Magistral 24B - Same. Repeated the loop and never wrote a file. (See screenshot)
—
Last image is Opus 4.6 for comparison. Network graph decorations, gradient effects, clean text hierarchy. The gap is still visible but GLM 4.7 Flash got closer than I expected.
Everyone benchmarks local LLMs on some standard benchmark. I do it on a real daily use case.
Multi-step agentic workflows where the model reads context, makes real world decisions, and writes a complete file - that is where you see the real gap.
GLM 4.7 Flash probably got the closest I have seen from any local model. I think it is usable for some tasks now.
#AI #ClaudeCode #LocalLLM
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in AI Agents

Context is king in AI. Five Claude Code features to manage context, and when to use them.
A learner from my class told me his biggest takeaway was how important context management is. I agree completely. Most people who pick up Claude Code focus o...

The Worst Job Displacement of Software Engineers Is Yet to Come.
This is not another fear mongering post.
What’s the most common hallucination you've seen from an LLM?
For me, it’s when you ask, “How do I do X in Y app or software?”
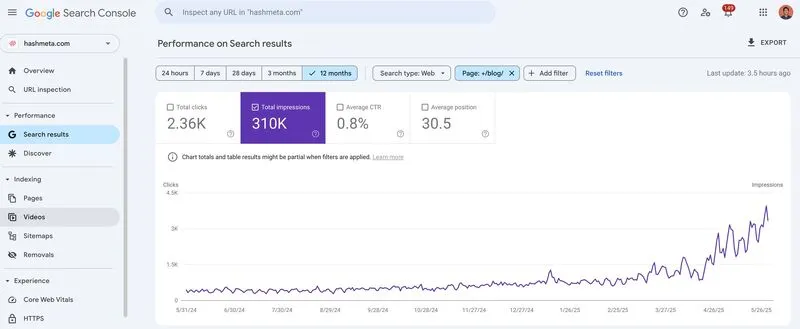
How We Turned 12 Years of Expertise Into an AI-Powered Service That Scales
Terrence Ngu Teck Kong has been running Hashmeta Group, a digital marketing agency, for 12 years.

Can LLMs like ChatGPT do reasoning? It failed my casual tests in under 30 minutes.
… more

Can DeepSeek R1 Run on a Normal Laptop for Free?
TL;DR
Context is king in AI. Five Claude Code features to manage context, and when to use them.
A learner from my class told me his biggest takeaway was how important context management is. I agree completely. Most people who pick up Claude Code focus o...
How We Turned 12 Years of Expertise Into an AI-Powered Service That Scales
Terrence Ngu Teck Kong has been running Hashmeta Group, a digital marketing agency, for 12 years.
Can DeepSeek R1 Run on a Normal Laptop for Free?
TL;DR
The Worst Job Displacement of Software Engineers Is Yet to Come.
This is not another fear mongering post.
What’s the most common hallucination you've seen from an LLM?
For me, it’s when you ask, “How do I do X in Y app or software?”
Can LLMs like ChatGPT do reasoning? It failed my casual tests in under 30 minutes.
… more