Why llms.txt Is a Bad Idea for the Web
But seeing "SEO gurus" promote it on authoritative platforms like Search Engine Land and Yoast SEO worries me.

But seeing “SEO gurus” promote it on authoritative platforms like Search Engine Land and Yoast SEO worries me.
--- TL;DR ---
🚫 What’s wrong with llms.txt? 🛑 It invites keyword stuffing 2.0 🛑 It creates a parallel web for AI, not humans 🛑 It burdens developers with unnecessary file management 🛑 It breaks user trust in AI responses
Let’s not optimize for manipulation. Let’s build for meaning. Let’s share this post to prevent AI regression.
--- Details ---
Let me explain.
What is it?
It is a proposed new standard that allows website owners to tell AI models what their site is about by publishing a /llms.txt file on their website. Think of it like keyword metadata for search engines, except this time, it’s a file with curated contents for large language models (LLMs). It was created with good intentions: to help LLMs better understand your site.
What do SEOs think about it?
Exactly what you’re imagining. “Oh, great, a new way to tell the AI what we want it to know, let’s stuff it with keywords, content, and marketing fluff to get into AI answers!”
Imagine giving every marketer a backstage pass to whisper in AI’s ear. That’s what llms.txt enables: unmoderated influence over LLM answers.
It’s déjà vu all over again. We’ve seen this with the keywords meta tag. Google deprecated it for a reason as it suffered from keyword stuffing. Now we’re inviting the same mess back in the LLM era, with content stuffing.
The deeper issue?
The author is solving a technical problem for LLM data collection. But the moment SEOs get wind of it, it becomes a game of “how to manipulate LLMs to hallucinate my site into every answer.” It’s not helpful. It’s harmful. And it breaks the long-term trust in AI-generated answers.
It gets worse. The author is even suggesting websites provide a *.md markdown version of their content. Can you imagine the nightmare this introduces to website dev? Every CMS, website owner will now be expected to maintain another file, just so AI can maybe read your site better?
We are building a parallel invisible web just to spoon-feed AI. This is already off the rails.
We’ve been here before. We saw what happened with meta keywords. Let’s not repeat the mistakes of the past.
Let AI learn to see the web like humans do, not rely on a hacked-up cheat sheet written by marketers.
We should instead make HTML more parseable. How about making Markdown native in HTML, like introducing a <markdown> tag?
What can we do to prevent this AI regression? 🛑 Speak up before llms.txt becomes the next SEO abuse playbook. 🛑 Jeremy Howard please stop promoting this. Your intention is good. Thanks, but no thanks. 🛑 Share this if you agree, we need a better way forward.
#AI #SEO #GEO #AEO #LLM #MachineLearning #ArtificialIntelligence #TechEthics #AITraining #DataCollection
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in AI Marketing

No, Karpathy Didn’t Say Vibe Coding Doesn’t Work
This starkly contrasts with my own experience.

Does AI have empathy? I asked Claude a simple product question.
The answer surprised me.
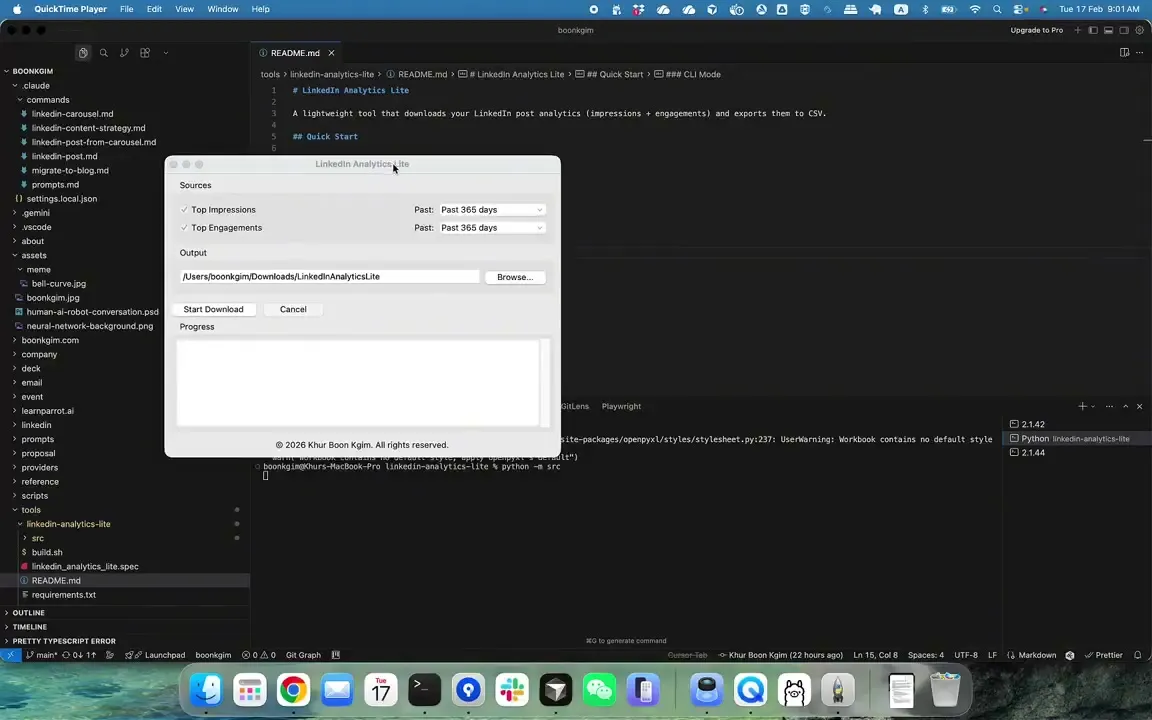
Not every automation needs an AI agent. After burning $25+ with a browser agent just to download analytics of my top LinkedIn posts, I decided to build a simple automation tool that costs nothing to run.
--

Lessons I Learned Coding 10+ Apps with Claude Code. Transferrable to Non-Coding.
Thanks to Chris Pecaut for the invitation. Great to be on stage with Darryl WONG, Gaurav Manek, and Gaurav Keerthi.

Why you should get AI to replace you
The CEO knows this is the main friction to AI adoption in his company. The sharing addresses this question. This article is the written version of that shari...

Congrats to cohort #2 for surviving the "torture" of my Foundations of Claude Code workshop.
Since cohort #1, the feedback has been all over the place. Same workshop, very different reactions:
No, Karpathy Didn’t Say Vibe Coding Doesn’t Work
This starkly contrasts with my own experience.
Lessons I Learned Coding 10+ Apps with Claude Code. Transferrable to Non-Coding.
Thanks to Chris Pecaut for the invitation. Great to be on stage with Darryl WONG, Gaurav Manek, and Gaurav Keerthi.
Why you should get AI to replace you
The CEO knows this is the main friction to AI adoption in his company. The sharing addresses this question. This article is the written version of that shari...
Does AI have empathy? I asked Claude a simple product question.
The answer surprised me.
Not every automation needs an AI agent. After burning $25+ with a browser agent just to download analytics of my top LinkedIn posts, I decided to build a simple automation tool that costs nothing to run.
--
Congrats to cohort #2 for surviving the "torture" of my Foundations of Claude Code workshop.
Since cohort #1, the feedback has been all over the place. Same workshop, very different reactions: