I am disappointed that Opus 4.8 still breaks one of the most basic rules in database design.
8 months ago, I noticed Opus 4.5 was not good at database design. So I built a DB design skill loaded with best practices.
8 months ago, I noticed Opus 4.5 was not good at database design. So I built a DB design skill loaded with best practices.
Today, despite model updates to Opus 4.8 and the skill, it still trips on the basics.
The rule it broke:
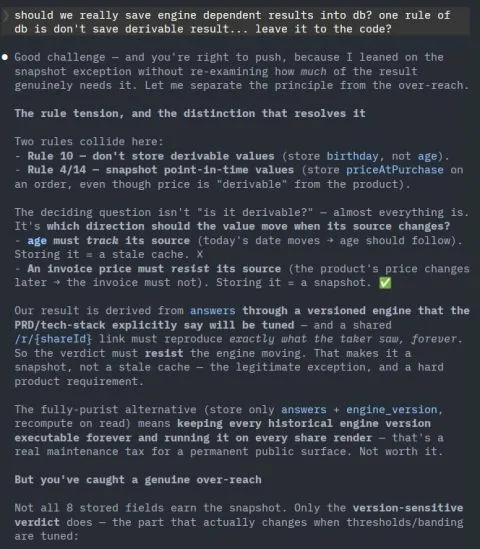
Store factual data (e.g. user input) and not derived data. If you can compute a value from data you already have, compute it, don’t save it. The only exception is when the calculation is genuinely expensive, then you cache it for performance.
Why this matters for data integrity: derived data is just a saved copy of a calculation. The moment the source data or the formula changes, that copy is stale. Now you have two answers to the same question, the stored one and the freshly computed one, and they disagree. Your database is asserting something the rest of your system no longer agrees with. That is the integrity bug, and it is silent until someone trusts the wrong number.
Yesterday I started building a new app, an AI readiness test. It asks an org 12 questions, runs the answers through a scoring engine, and hands back a “position” (where you sit on the readiness ladder) plus the one binding constraint holding you back. No overall score, by design.
The schema Opus 4.8 proposed stored the user’s answers and 8 derived results: the position, the confidence flag, the binding constraint, the per-dimension levels, the fill percentages, and more.
Every one of those is computed from two things: the user’s answers and the engine’s params.
In an assessment, a user won’t expect the result to change in the future, but saving the result can still cause confusion later.
If the assessment logic changes in the future, the saved results will be out of sync with what the new code computes from the same answers. Someone opening the database later sees a row that doesn’t reconcile and reasonably concludes it’s a bug or corrupted data.
The better way: store the answers. Store the engine version and its tunable params (the thresholds). Then recompute the position on read.
Why this is strictly better:
-
No data-integrity trap. Recomputing from the stored answers plus stored params with a version-controlled engine always reconciles.
-
It’s normalized. No derived output duplicated in the table.
What disappoints me is that the schema was proposed by the frontier model everyone is hyping right now.
With all the promise from the frontier labs, and all the hype around Mythos 5 and Fable 5, AI still trips on basic database design.
If you are shipping with AI and you don’t yet know what good looks like, you won’t catch this, and the model won’t catch it for you.
Despite all the promise, I don’t see AI replacing good software engineers yet if it still makes such basic mistakes.
#AI #ClaudeCode #VibeCoding #DatabaseDesign #BuildInPublic
Tap to expand
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in Vibe Coding
I finally went down the rabbit hole.
After resisting for months, I subscribed to Claude Max 20x.
Opus 4.5 refused to work OT recently. So I interviewed 7 free candidates.
Claude Code with Opus 4.5 has been my most productive team member for the past 3 months.

Hot Take: Vibe Coding Won't Replace Software Engineers
Here, I share my journey from a strong believer to a skeptic.
Hitting your AI coding usage limit feels like reaching the climax of a drama series and having to...
You’re full of ideas, but suddenly on hold until next day.

What Publishers Think About AI Image Generation
I couldn’t find the original source of the meme—happy to credit the author if anyone knows the source.
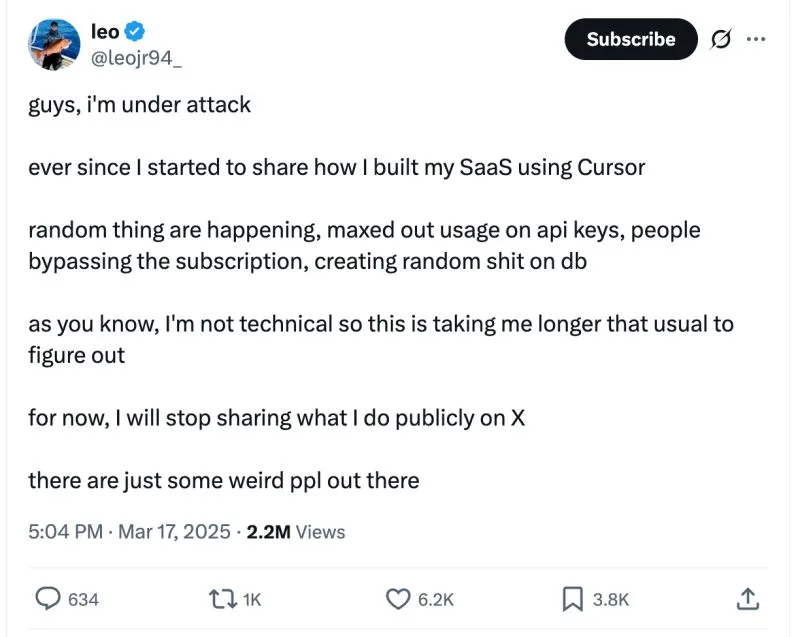
"Guys, I’m under attack"
I came across this post where a founder shared how his SaaS got exploited right after he started sharing how he built his SaaS using Cursor.
I finally went down the rabbit hole.
After resisting for months, I subscribed to Claude Max 20x.
Hot Take: Vibe Coding Won't Replace Software Engineers
Here, I share my journey from a strong believer to a skeptic.
What Publishers Think About AI Image Generation
I couldn’t find the original source of the meme—happy to credit the author if anyone knows the source.
Opus 4.5 refused to work OT recently. So I interviewed 7 free candidates.
Claude Code with Opus 4.5 has been my most productive team member for the past 3 months.
Hitting your AI coding usage limit feels like reaching the climax of a drama series and having to...
You’re full of ideas, but suddenly on hold until next day.
"Guys, I’m under attack"
I came across this post where a founder shared how his SaaS got exploited right after he started sharing how he built his SaaS using Cursor.