Most people design AI agent systems wrong. They put AI agents inside the security boundary instead of outside. This exposes their system to prompt injection.
--
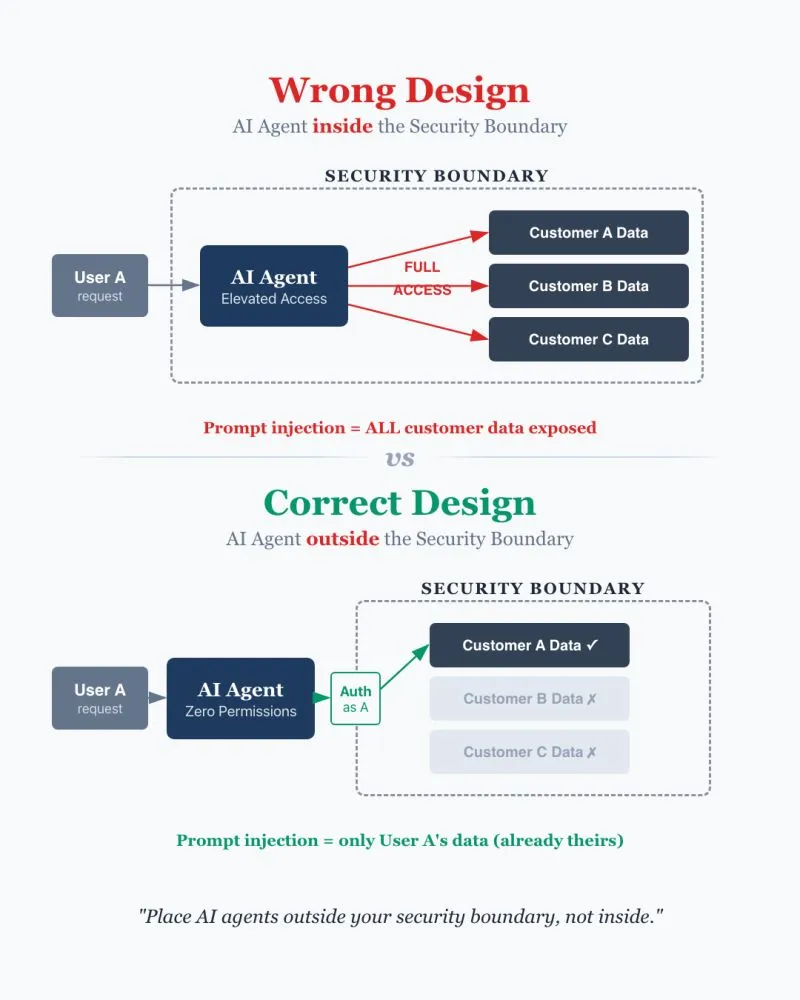
—
Most systems treat AI agents as internal users. For example, an AI Customer Service Agent is usually given the same elevated access as a human CS agent - access to all customer records, order history, account details.
This feels natural. The AI agent is doing the same job, so it gets the same access.
But this is where things go wrong.
If prompt injection succeeds even once, the attacker gets access to everything that agent can see. Every customer’s data.
And prompt injection WILL succeed eventually. LLMs are probabilistic. When the user’s instruction conflicts with ours, we can’t guarantee the LLM will always follow ours.
The two most common defenses are flawed:
- Instruct the AI agent to reject customers if they asked for unauthorized info.
- Add another LLM as a guardrail to detect prompt injection.
Both rely on the same thing - an LLM following OUR instructions 100% of the time.
You can stack guardrails on top of guardrails. It will still be probabilistic.
Even if you can lower the probability, AI agents are usually exposed to huge volume of untrusted input from email, chat, forum and more. Processing high volume of input means it eventually will happen.
—
The fix is simpler than most teams realize.
Instead of treating AI agents as internal users with elevated permissions, treat them as external users.
Place AI agents outside your security boundary, not inside.
Here is how:
-
Zero permissions by default
-
No elevated access. No shared service accounts.
-
The AI agent starts like any unauthenticated external user.
-
Authenticate on behalf of the user
-
If the agent needs User A’s records, it authenticates only as User A’s agent.
-
The AI agent asks for credentials from the user and logs in on their behalf.
-
Even if prompt injection succeeds, the agent can only access what that user already has access to.
-
Existing security handles the rest
-
Rate limiting, access controls, audit logs - already designed for external users.
-
All of this applies to the AI agent automatically with minimal tweaks.
—
Zero trust architecture has been around for years. Instead of building LLM guardrails as new layers, a simpler way is to apply what we already know to a new actor.
If your AI agent sits inside your security boundary with the same permissions as your internal team, prompt injection is a matter of when, not if. Move it outside, and your existing security infrastructure does most of the work.
—
What if the agent must be internal?
- Internal agents should only process input from trusted sources.
- Never expose an internal agent to untrusted input such as emails, forum posts, or 3rd party content.
- Untrusted input + elevated permissions = prompt injection surface.
#Security #PromptInjection #AIAgents #SoftwareArchitecture
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in AI Security

Why you should get AI to replace you
The CEO knows this is the main friction to AI adoption in his company. The sharing addresses this question. This article is the written version of that shari...
What is an AI agent?
If you're still confused, you're not alone. There is no universally agreed-upon definition of what an AI agent is.

Business Plus AI Forum @ Beijing CIFTIS 2025 | Global Online Free Live Stream
We are proud to share that we are bringing Business Plus AI Forum to CIFTIS 2025, one of the largest trade fairs in China. Join us on Saturday, September 13,...

Forget Pain Points: Think Convenience
This advice from Ev Williams, co-founder of Blogger, Twitter and Medium should serve as a signpost.

Good news!
What makes Eu Gene's training unique is that it's not only insightful but also entertaining and highly engaging.
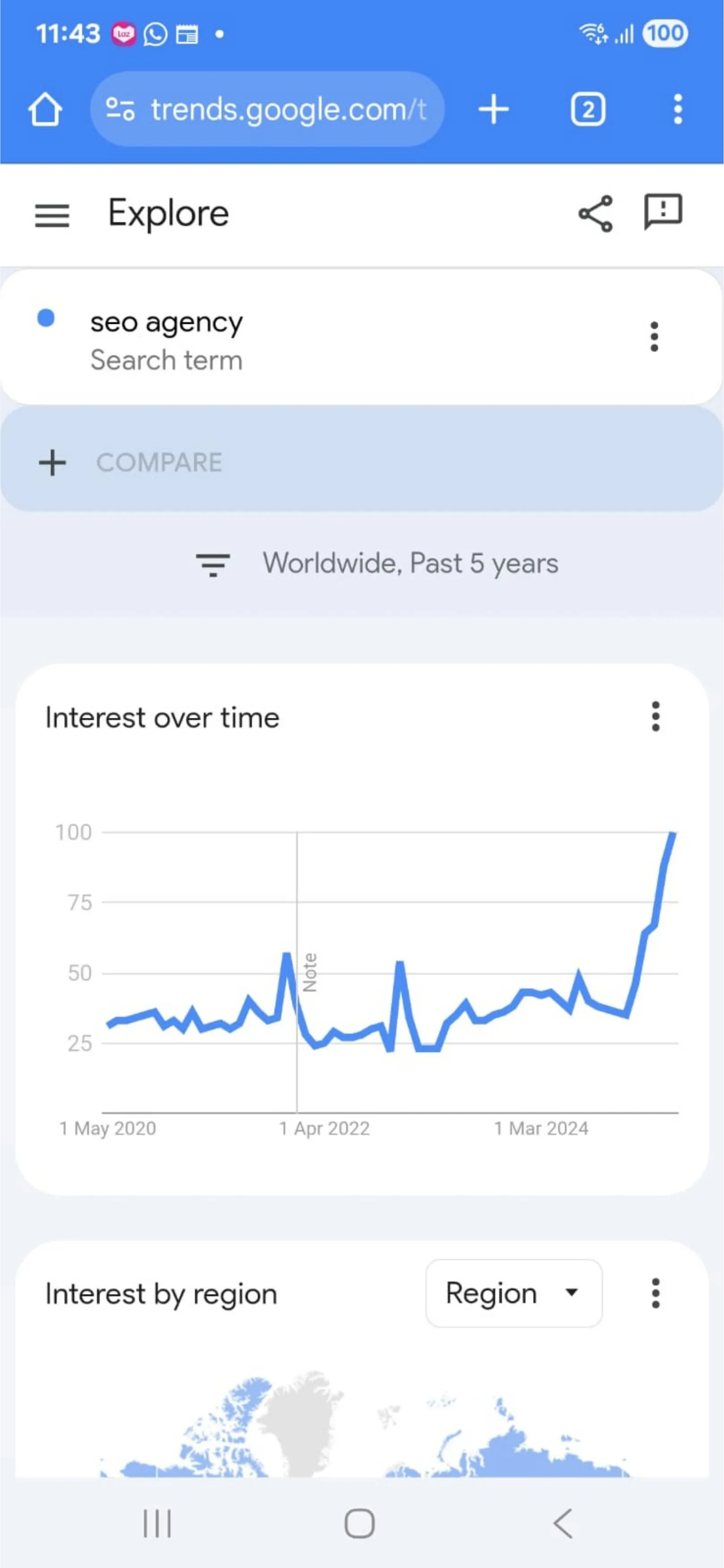
Many think SEO is dying. It's actually flying.
Just look at the trend 📈. Global searches for "SEO agency" are at a 5-year high (see graph).
Why you should get AI to replace you
The CEO knows this is the main friction to AI adoption in his company. The sharing addresses this question. This article is the written version of that shari...
Forget Pain Points: Think Convenience
This advice from Ev Williams, co-founder of Blogger, Twitter and Medium should serve as a signpost.
Good news!
What makes Eu Gene's training unique is that it's not only insightful but also entertaining and highly engaging.
What is an AI agent?
If you're still confused, you're not alone. There is no universally agreed-upon definition of what an AI agent is.
Business Plus AI Forum @ Beijing CIFTIS 2025 | Global Online Free Live Stream
We are proud to share that we are bringing Business Plus AI Forum to CIFTIS 2025, one of the largest trade fairs in China. Join us on Saturday, September 13,...
Many think SEO is dying. It's actually flying.
Just look at the trend 📈. Global searches for "SEO agency" are at a 5-year high (see graph).