AI failed at 96% of jobs.
A new report from Scale AI and the Center for AI Safety tested AI agents against 240 real freelance projects from Upwork. The best agent completed only 2.5% ...

A new report from Scale AI and the Center for AI Safety tested AI agents against 240 real freelance projects from Upwork. The best agent completed only 2.5% of them to acceptable quality.
The report: https://lnkd.in/gnSb7MPJ
Meanwhile, on the same feed, founders are claiming AI replaced half their team.
Same AI models. Opposite conclusions.
My personal take is the researchers may not have the domain expertise to automate the work they were testing. I know some tech-savvy entrepreneurs (including myself) who are already automating some work that, in the past, would have required hiring people.
The difference has nothing to do with AI capability.
It’s a difference in mental model when using AI.
One group expects AI to be an expert of all trades.
They give AI the brief, expect senior-level output, and dismiss it when the result is average.
“See? AI is overhyped.”
The other group treats AI like a junior employee.
They know LLMs are an averaging technology - the output converges to the statistical mean of its training data. By design. This means average output.
So they don’t expect expert output out of the box.
They invest in “training” the junior.
Curate skill files written by domain experts.
Build workflows based on domain knowledge.
Write detailed specifications.
Review, iterate, refine.
That’s when the output stops looking “average.”
I’ve been both groups.
When I first started building apps with Claude Code, I threw a PRD at it and got demos that broke in production. Classic Group 1.
3 production apps later, I now write detailed project files, create expert skill specifications, and treat every AI session like onboarding a new hire.
Same tool. Completely different output.
This pattern holds across functions:
-
A marketer who loads brand voice and campaign references gets strategic output. One who types “write me an ad” gets slop.
-
A developer who gives detailed specs and test harnesses gets production code. One who says “build me an app” gets a demo.
The difference is never the AI.
Next time an AI tool disappoints you, check your workflow. Not the model.
LLMs produce average output by design. The expert’s job is to guide it to raise the ceiling.
#AI #AIAgents #LLM #ExpertInTheLoop
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in Tech & Startup
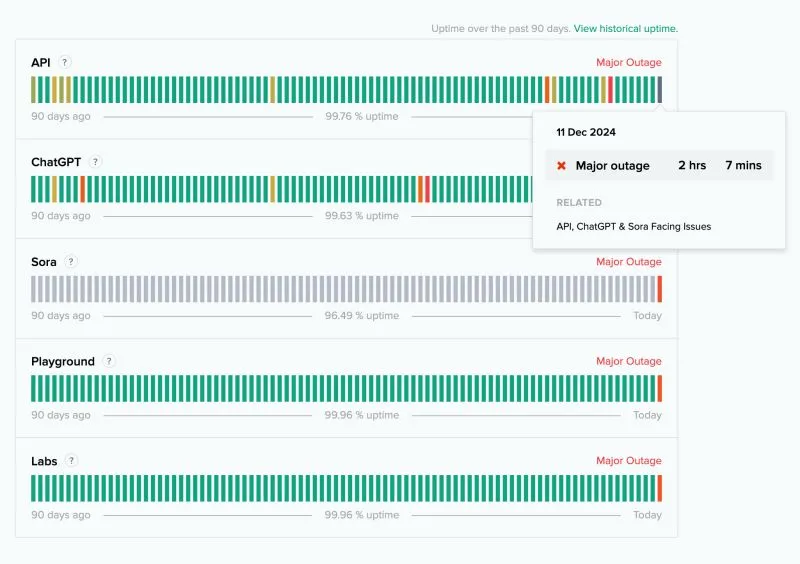
**GenAI Pitfalls**
ChatGPT has recently encountered various outages. These outages took down our AI services and disrupted business operations, both for us and our clients.

I am honored to be featured by e27 (Optimatic), one of the top startup media and communities in the...
"You can't connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your fut...

When a “useless” feature becomes the delightful differentiator
It is a little pet that lives inside Codex. It does not write code, catch bugs, or make anything faster. By every rational measure of a coding agent, it is p...

5 Advanced Prompting Techniques That’ll Instantly Improve Your Results with ChatGPT (or Any LLM)
Most people stop at "Act as a..." or “Write me a...”.
Google is steadily expanding its moats for GenAI again.
Google started as a laughing stock in the GenAI arms race with the failed Bard demo.

Most startups' growth stalls because they pour users into a leaky bucket.
That is why you should look at AARRR not as a funnel but as loops.
**GenAI Pitfalls**
ChatGPT has recently encountered various outages. These outages took down our AI services and disrupted business operations, both for us and our clients.
When a “useless” feature becomes the delightful differentiator
It is a little pet that lives inside Codex. It does not write code, catch bugs, or make anything faster. By every rational measure of a coding agent, it is p...
5 Advanced Prompting Techniques That’ll Instantly Improve Your Results with ChatGPT (or Any LLM)
Most people stop at "Act as a..." or “Write me a...”.
I am honored to be featured by e27 (Optimatic), one of the top startup media and communities in the...
"You can't connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your fut...
Google is steadily expanding its moats for GenAI again.
Google started as a laughing stock in the GenAI arms race with the failed Bard demo.
Most startups' growth stalls because they pour users into a leaky bucket.
That is why you should look at AARRR not as a funnel but as loops.