How to Push AI Output Quality Using the Generator-Evaluator Pattern
It is called "Harness Design for Long-Running Application Development" and it reads like a technical deep-dive on building front-end applications with AI. Mo...
Anthropic just published an engineering blog post that I think most people will miss.
It is called Harness Design for Long-Running Application Development and it reads like a technical deep-dive on building front-end applications with AI. Most non-developers will probably skip it.
I think that is a mistake.
Because the core pattern they describe - Planner, Generator, Evaluator - applies to any work where you want to push AI output from average to good, not just coding. And if it sounds familiar, it is. It is the same reflection pattern that Andrew Ng has been talking about. The Anthropic team just showed what it looks like when you implement it as agent skills and subagents.
Here is my summary of the 6 most useful tips from the article, and why I think they work beyond coding.
The Core Problem: Quality Drops as Context Fills Up
If you have used AI for anything beyond a single prompt, you have probably noticed this: the output gets worse the longer the task runs.
As the context window fills up, AI models lose coherence. The Anthropic team observed this directly - some models even exhibit what they call “context anxiety,” rushing to wrap up when they sense the context getting full. The output becomes shallow, generic, or inconsistent with what came before.
And here is the part most people miss: this compounds across handovers.
When you break a large task into steps - plan first, then execute, then refine - each step inherits the degraded context from the previous one. Step 2 works with step 1’s imperfect output. Step 3 compounds the drift from step 2. By the end, you are several layers removed from your original intent.
This is why the Anthropic team’s solo run (one agent, no harness) resulted in broken core functionality. Not because the model could not do the work, but because quality degraded faster than the task progressed.
The Quick Fix That Does Not Work: Ask AI to Review Itself
The intuitive response to dropping quality is to ask the AI to evaluate its own work. Generate something, then ask “is this good?”
The Anthropic team tried this. When they asked the same AI agent to generate work and then evaluate that same work, the agent “confidently praised output even when quality was mediocre.” The self-evaluation bias gets worse with subjective tasks - anything without a clear right or wrong answer.
Anyone who has used AI for writing, design, or marketing copy has experienced this. Ask Claude or ChatGPT to write something, then ask it to review what it just wrote. It will almost always say it is good. Maybe suggest minor tweaks. But it will rarely tell you “this is mediocre, start over.”
This is not a bug. This is how LLMs work. They are probabilistic machines optimized to be helpful, which means they lean toward positive assessment of their own output.
So the quick fix - asking the generator to grade itself - does not work. The fix is to separate the generator from the evaluator.
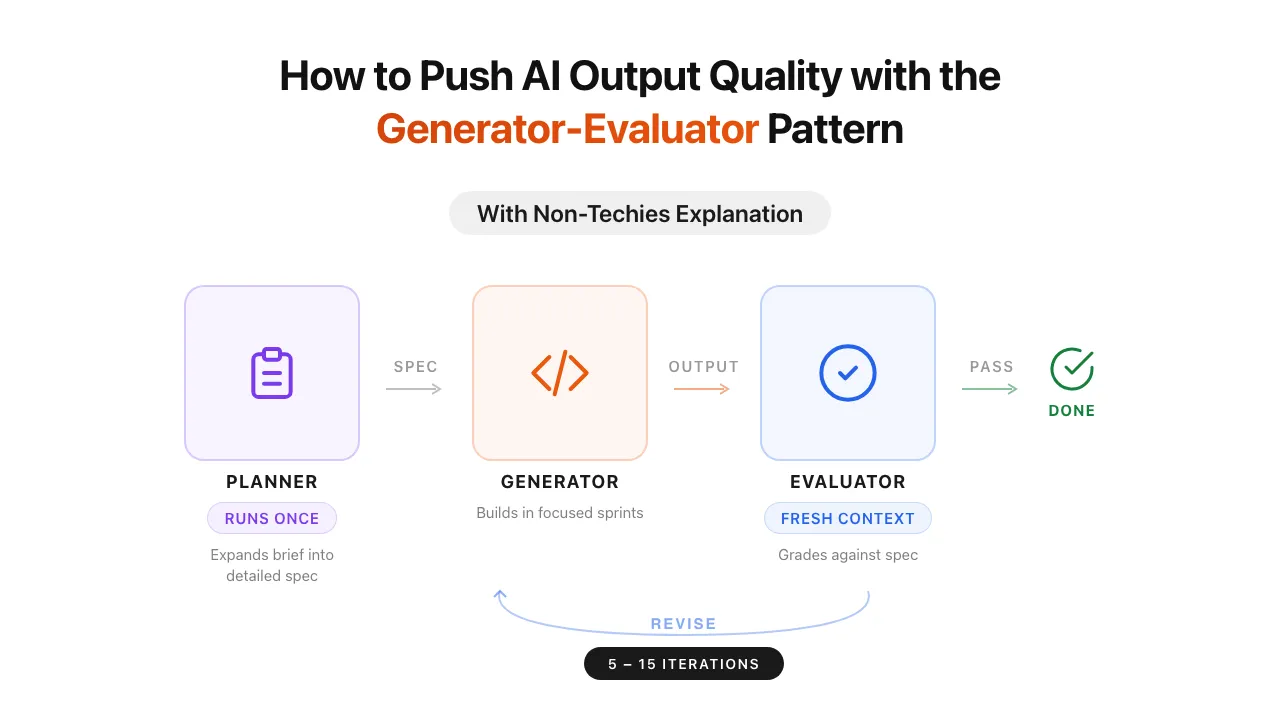
The Architecture: Planner + Generator + Evaluator
The Anthropic team used a three-agent system:
- Planner - Runs once upfront. Takes a vague brief and expands it into a detailed specification. Fills in the gaps the user did not think to specify.
- Generator - Takes the specification and does the actual work in focused sprints, picking up one feature at a time.
- Evaluator - Tests and grades the output against the specification. Sends it back for revision if it does not pass.
The generator and evaluator work in a loop - 5 to 15 iterations per task. The evaluator keeps sending work back until it meets the bar. The planner is not part of this loop. It delivers the spec and steps aside.
The key difference from asking the generator to review itself: the evaluator starts with a fresh context. It does not carry the generator’s previous context that may influence its evaluation. It sees the work with clear eyes and grades it against the specification, not against its own memory of what it was trying to do.
This is essentially Andrew Ng’s “reflection” pattern - one of the most effective agentic design patterns. The generator produces, the evaluator reflects, and the cycle repeats until quality improves.
The Anthropic team just showed what it looks like when you implement it seriously, with real grading criteria and sprint contracts.
6 Tips From the Article (That Work Beyond Coding)
1. Define grading criteria before the work starts
The Anthropic team defined four top-level dimensions for evaluating front-end design: design quality, originality, craft, and functionality. Each one had a specific definition. These are not the only criteria - one sprint alone had 27 detailed criteria. But the top-level dimensions tell the evaluator what matters most. The team even weighted them, emphasizing design quality and originality over craft and functionality because the model already performed well on the latter two.
Why: Without clear criteria, the evaluator defaults to “looks good to me.” This is the same problem when you ask AI to “review” something without telling it what good looks like.
How: Before you ask AI to generate anything important, define the dimensions you care about and what “good” looks like for each. Be specific. “Good writing” is useless. “Clear, uses concrete examples, actionable, and addresses the reader’s specific objection” is useful. The detailed per-sprint criteria come later (see sprint contracts below).
2. Break work into smaller chunks
The generator worked in sprints - feature by feature - rather than trying to do everything at once.
Why: AI context windows degrade on long tasks. The model loses coherence. The article mentions that some models even exhibit “context anxiety” - they start rushing to wrap up when they sense the context getting full. I have seen this myself with Claude Code on larger features.
How: For any task longer than a single prompt-response cycle, break it into pieces. Write one section at a time. Build one feature at a time. Review and approve each piece before moving to the next.
3. Use sprint contracts
Once you have your chunks, the next question is how to manage each one. Before each sprint, the generator and evaluator negotiated a “sprint contract” - agreeing on what “done” looked like for that chunk before any work started. The generator proposed what it would build and how success would be verified. The evaluator reviewed the proposal. The two iterated until they agreed.
One sprint alone had 27 criteria covering a single feature - including specific test cases like whether users could reorder items or delete elements through the API.
Why: The overall spec was intentionally high-level. Sprint contracts bridged the gap between vague user stories and testable implementation. Without them, the evaluator does not know what to check and the generator drifts.
How: For each chunk, write out what “done” looks like before you start generating. This works for articles, marketing campaigns, product specs - anything with multiple parts.
4. The words in your criteria shape the output
The article mentions that specific words in their evaluation criteria directly shaped the character of the output. For example, using “museum quality” in the criteria influenced the aesthetic direction of the generated design.
Why: Your evaluation criteria are not just for grading. They leak into what gets produced through the feedback loop. The generator adapts to what the evaluator rewards.
How: Pay attention to the adjectives and reference points in your criteria. “Professional and clean” will produce different output than “bold and distinctive.” Choose your words deliberately - they are instructions, not just a scorecard.
5. Tune the evaluator to be skeptical
The Anthropic team found that early versions of their evaluator were too lenient. They had to iteratively tune it to be more critical.
Why: The default behavior of most AI is to be agreeable and positive. If you do not actively push for skepticism, your evaluator becomes a rubber stamp.
How: When setting up an evaluator prompt, add explicit instructions like “Be skeptical. If the output is merely adequate, grade it as failing. Only pass output that genuinely meets all criteria.” You will probably need to adjust this a few times. The Anthropic team did too.
6. Remove scaffolding when the model improves
When the team moved to a newer model (Claude Opus 4.6), they could remove the sprint decomposition entirely while maintaining quality.
Why: Workflows that were necessary six months ago might be unnecessary overhead today. If you are still using the same elaborate multi-step prompting from early 2025, you could be adding complexity that no longer helps.
How: Periodically test whether your scaffolding is still needed. Run a simplified version and compare the output. If the model handles it without the extra steps, simplify. Complexity should match the problem, not your habits from an older model.
Why This Matters Beyond Code
The article uses coding and front-end design as examples. But the pattern works for anything subjective or complex where quality matters.
Writing a marketing brief? One agent plans the structure, another writes it, a third evaluates it against your brand guidelines.
Building a strategy document? One agent expands the brief into a detailed outline, another drafts each section, a third checks for logical consistency and gaps.
The principle is separation of concerns. The same principle that works in software architecture, organizational design, and quality assurance. You would not ask the person who wrote the report to be the only reviewer. Same logic applies to AI.
The Numbers
The solo run (one agent, no harness) cost $9 and took 20 minutes. The harness run (planner + generator + evaluator loop) cost $200 and took 6 hours. The harness output had working features. The solo output had broken core functionality.
The Anthropic team is honest about the trade-off. The same fresh context that makes the evaluator effective also adds orchestration complexity, token overhead, and latency to every run. And even with the full harness, imperfections remained - small issues that slipped through despite multiple QA cycles.
Their advice: the evaluator is not a fixed yes-or-no decision. It is worth the cost when the task sits beyond what the current model does reliably solo. As models improve, that boundary moves outward, and the overhead becomes unnecessary for tasks the model now handles on its own.
I think for most of us, the practical takeaway is not to run $200 harnesses. It is that even a simple version of this pattern - write criteria, generate, evaluate with a separate prompt, revise - will push your output quality significantly compared to “ask AI once and use whatever it gives you.”
If you are a founder or builder using AI for work that matters, the gap between single-prompt output and a generate-evaluate loop is probably bigger than you think. And if you have been wondering why your AI output feels “good enough but not great,” this is probably why - you are asking the same AI to both generate and judge its own work.
#AI #Productivity #SoftwareEngineering #ArtificialIntelligence #AgentDesign
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in Tech & Startup

Google's VP of Product recently answered a question about AEO/GEO for AI Search.
Here are some key takeaways:

Joining an AI Strategy Panel at NTU EEE Alumni Event
Whether you’re deep in engineering, building your start-up, crafting user experiences, or leading teams – AI is reshaping all our paths right now.
A common question I get from my Foundations of Claude Code workshop learners:
"Is the website we built SEO and GEO optimised?"

Should You Listen to Customer Feedback?
This is one of the most debated topics in product development.

❌ One common mistake we keep seeing business owners make in marketing:
They hire a junior marketer to run ads, create content and post on social media... And think their marketing is covered.

OpenClaw Creator: Why 80% Of Apps Will Disappear
If you are still thinking OpenClaw is just hype, you should watch this interview with Peter Steinberger.
Google's VP of Product recently answered a question about AEO/GEO for AI Search.
Here are some key takeaways:
A common question I get from my Foundations of Claude Code workshop learners:
"Is the website we built SEO and GEO optimised?"
OpenClaw Creator: Why 80% Of Apps Will Disappear
If you are still thinking OpenClaw is just hype, you should watch this interview with Peter Steinberger.
Joining an AI Strategy Panel at NTU EEE Alumni Event
Whether you’re deep in engineering, building your start-up, crafting user experiences, or leading teams – AI is reshaping all our paths right now.
Should You Listen to Customer Feedback?
This is one of the most debated topics in product development.
❌ One common mistake we keep seeing business owners make in marketing:
They hire a junior marketer to run ads, create content and post on social media... And think their marketing is covered.