Your RAG System's Real Problem Isn't Hallucination
Two top common root causes are:
Tap a slide to expand













Two top common root causes are: → Poor data quality → Poor search implementation
Earlier, I shared tips about RAG search implementation: https://lnkd.in/gnWSTY9X
In this post, I would like to share on how to improve data quality with a 3-phase prioritization framework.
Note: All these are high impact and important prioritized by effort.
—
Phase 1 – Quick Wins (Low Effort)
Source Reliability & Whitelisting → Restrict ingestion to trusted, high-quality data sources. → Why important: Ensures foundational data accuracy. → Effort: Low, requires initial curation only.
Metadata & Provenance Tracking → Store author, date, and version info with each document. → Why important: Improves data traceability and accountability. → Effort: Low, can be automated during ingestion.
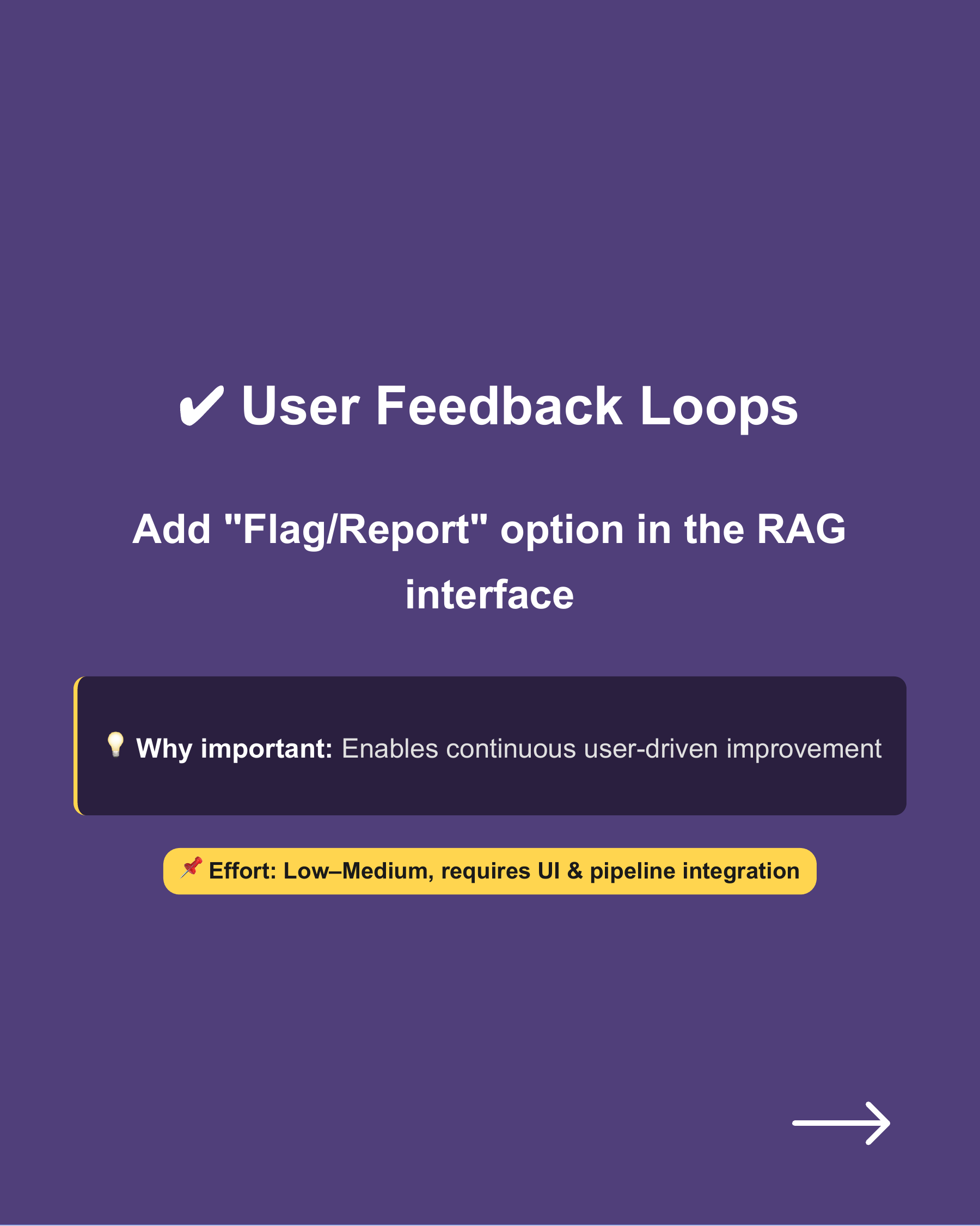
User Feedback Loops → Add “Flag/Report” option in the RAG interface. → Why important: Enables continuous user-driven improvement. → Effort: Low to medium, requires UI and pipeline integration.
—
Phase 2 – Medium-Term Enhancements (Medium Effort)
Data Quality Pipelines → Automate validation, deduplication, enrichment, and schema checks. → Why important: Enforces systematic quality control. → Effort: Medium, requires ETL/ELT pipeline setup.
Continuous Data Auditing → Scheduled scans for outdated, irrelevant, or broken documents. → Why important: Maintains data relevance and integrity. → Effort: Medium, requires monitoring dashboards.
Incremental Updates → Shift from bulk loads to small, validated batches. → Why important: Reduces error propagation and improves freshness. → Effort: Medium, requires ingestion pipeline redesign.
—
Phase 3 – Long-Term Maturity (High Effort)
Data Governance & Stewardship → Assign data owners and implement approval workflows. → Why important: Establishes clear ownership and accountability. → Effort: High, requires organizational alignment.
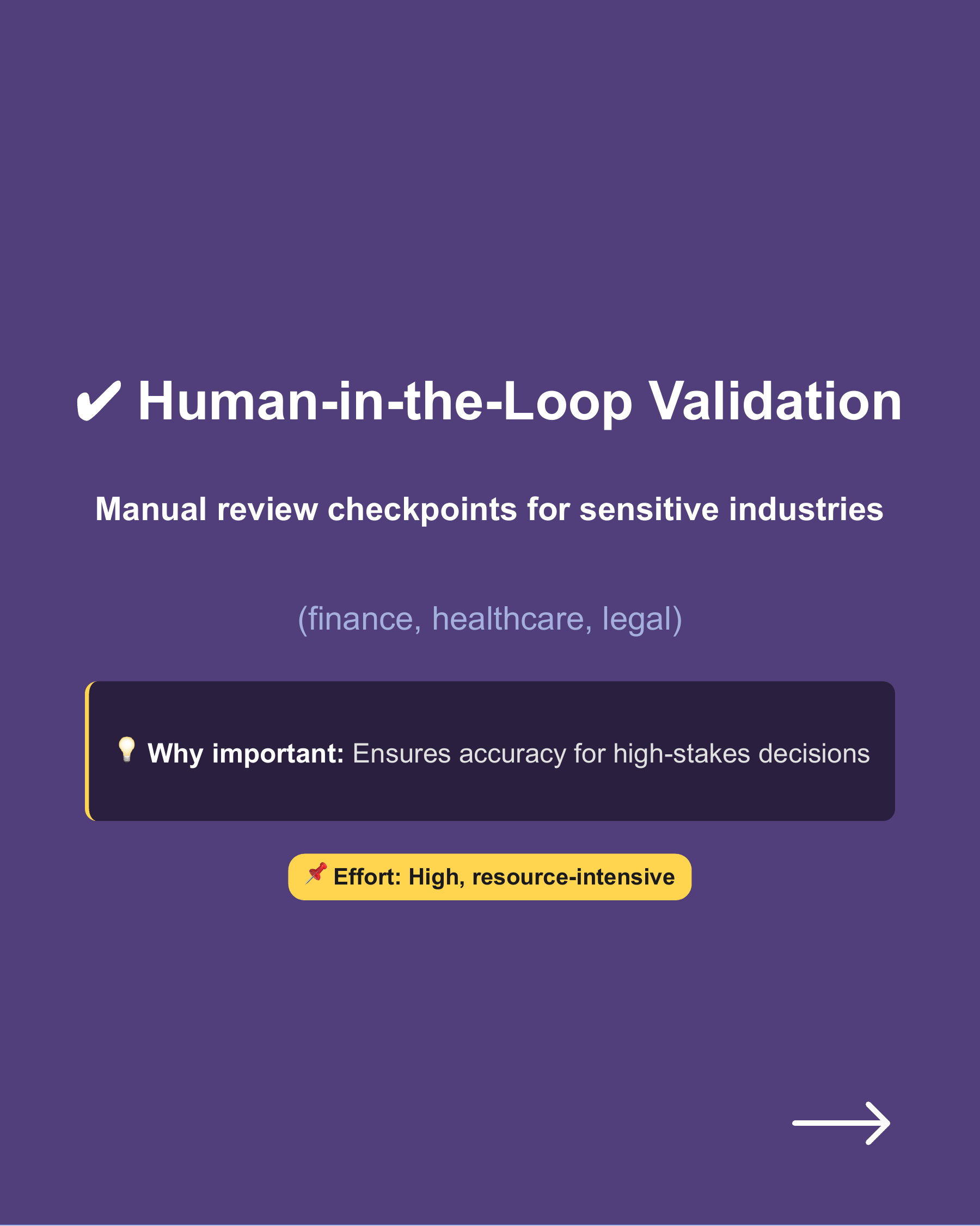
Human-in-the-Loop Validation for Critical Data → Manual review checkpoints for sensitive industries (finance, healthcare, legal). → Why important: Ensures accuracy for high-stakes decisions. → Effort: High, resource-intensive.
—
✅ Recommendation: → Start with Source Reliability, Metadata Tracking, and Feedback Loops (Phase 1, Low Effort) as they require minimal overhead. → Then scale into automated pipelines and auditing (Phase 2: Medium Effort) → Only then invest in formal governance and human validation (Phase 3: High Effort).
#RAG #LLM #EnterpriseRAG #GenAI #EnterpriseAI
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in AI Agents

Why GenAI Pilots Need Both Strategy and Execution
In the post, I shared 5 proven strategic frameworks to apply to find high-ROI AI opportunities.

Not all AI projects need data scientist and AI engineers.
One of the most common mistakes business leaders make in their AI project is getting the wrong team to build.

From insight to action: AI is not the future—it’s the now.
At the Business+AI Forum 2024, our speakers shared groundbreaking insights on how AI is transforming industries, creating opportunities, and solving real-wor...

The Charisma Business Coach (No.
OpenClaw vs Claude vs Hermes vs NanoClaw
If you have used Claude Code heavily, you saw it immediately: OpenClaw is a chat wrapper on top of CLI agents like Claude Code and Codex. So I dismissed it a...

"If you're good at badminton, don't train for a tennis competition."
This is something I've learned through experience as a serial technopreneur.
Why GenAI Pilots Need Both Strategy and Execution
In the post, I shared 5 proven strategic frameworks to apply to find high-ROI AI opportunities.
From insight to action: AI is not the future—it’s the now.
At the Business+AI Forum 2024, our speakers shared groundbreaking insights on how AI is transforming industries, creating opportunities, and solving real-wor...
"If you're good at badminton, don't train for a tennis competition."
This is something I've learned through experience as a serial technopreneur.
Not all AI projects need data scientist and AI engineers.
One of the most common mistakes business leaders make in their AI project is getting the wrong team to build.
The Charisma Business Coach (No.
OpenClaw vs Claude vs Hermes vs NanoClaw
If you have used Claude Code heavily, you saw it immediately: OpenClaw is a chat wrapper on top of CLI agents like Claude Code and Codex. So I dismissed it a...