Lessons I Learned Coding 10+ Apps with Claude Code. Transferrable to Non-Coding.
Thanks to Chris Pecaut for the invitation. Great to be on stage with Darryl WONG, Gaurav Manek, and Gaurav Keerthi.

I gave a talk last night at the Agentic Builders Collective meetup, in front of 100+ builders, on the two agentic patterns I use to fix Claude Code’s poor instruction-following. This article is the written version of that talk, with the slides included.
Thanks to Chris Pecaut for the invitation. Great to be on stage with Darryl WONG, Gaurav Manek , and Gaurav Keerthi.
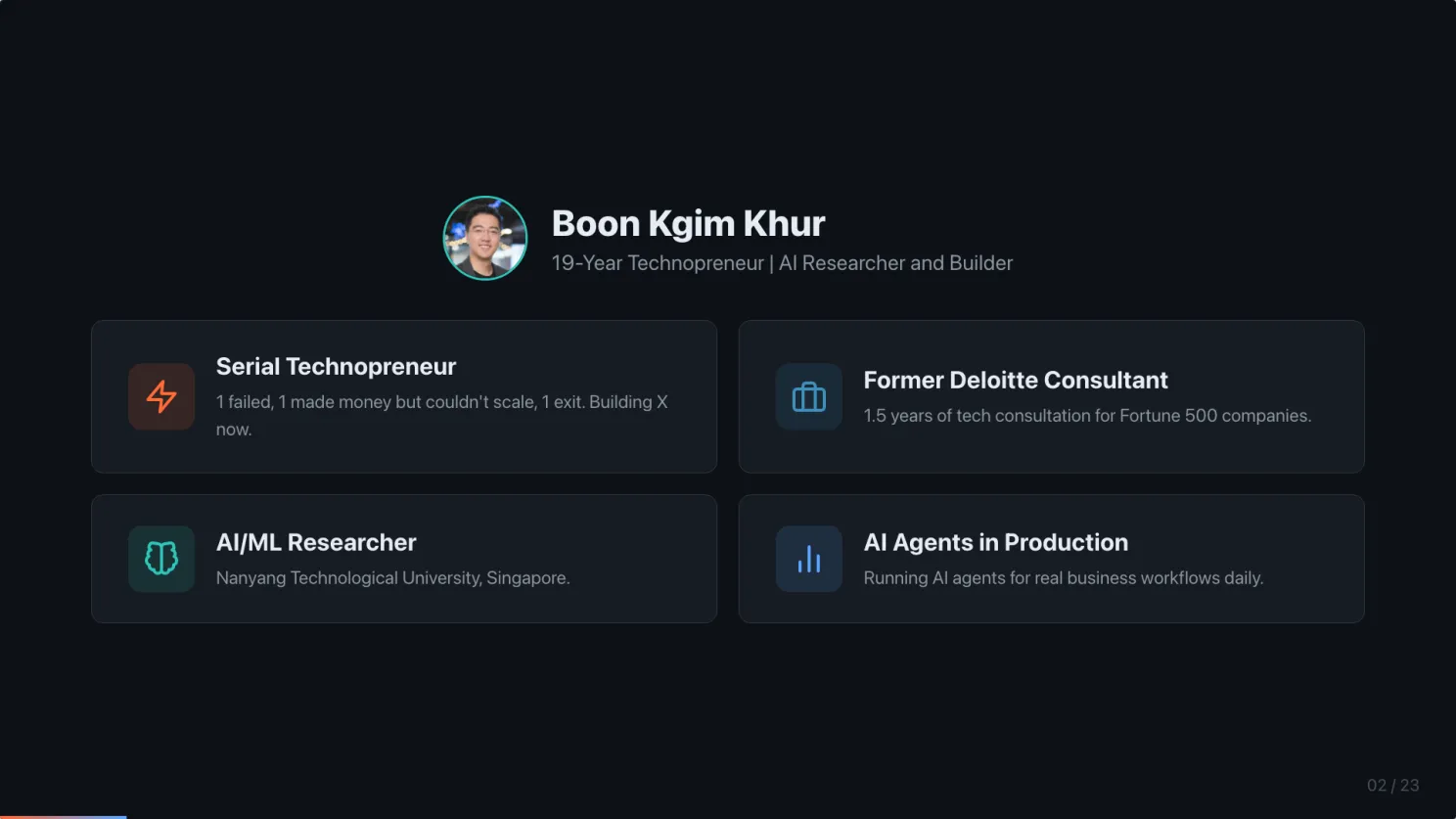
A quick intro about myself. I have been building tech solutions for 19 years. Multiple companies, one failed, one made money but could not scale, one exit, and a few I am building right now. AI and ML researcher at NTU. Founder at nanogent.ai, Dad at Learn Parrot, and CTO at Hashmeta Group. And every day I run AI agents in production for real business workflows.
The key highlight of the talk in one sentence:
Two agentic patterns I use to fix Claude Code’s poor instruction-following: Generator + Evaluator, and Thin Orchestrator + Specialized Workers. Both composed inside plain markdown skill files.
These patterns are applicable to any agent skills. They work on non-coding skills too.
I have built apps for 19 years. I know the pain of spaghetti code.
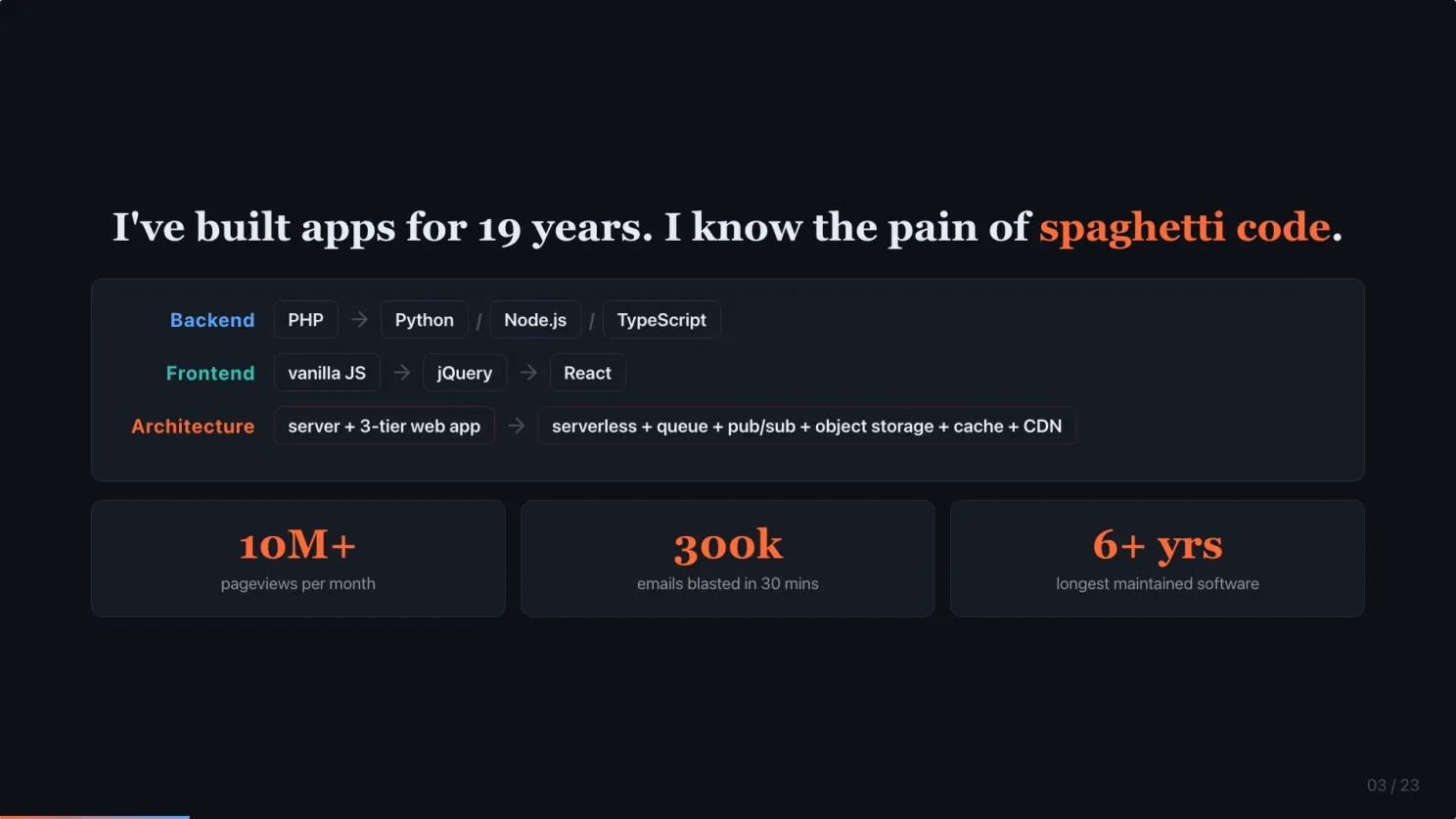
Quick credential. 19 years shipping software by hand. Backend started on PHP, then branched into Python, Node.js, and TypeScript. I still use all three. Frontend went from vanilla JavaScript through jQuery to React. Architecture went from a server running a 3-tier web app to serverless composed of queues, pub/sub, object storage, caches, CDNs, and a pile of other components.
Some of those apps served 10 million pageviews a month. Some blasted 300,000 emails within 30 minutes without the queue falling over. And one of them I have maintained for 6+ years.
That is where you learn, painfully, that clean and maintainable code is non-negotiable. It is the thing that decides whether your product survives past year two. I know the pain of spaghetti code. That knowledge is the quality bar I am bringing to the AI workflow I am about to share.
I want to build an AI system that can replace myself
Here is the goal I have been driving toward for the past 6 months.
I want to build an AI system that can replace myself. That means a system that can develop a production-grade app the way I would do it by hand. Clean code, scalable and secure architecture, nice UX/UI.
6 months in. 10+ projects shipped. 50+ skill files running in production. Code reviews, database audits, deployment plans, content pipelines. All solo. All markdown.
The patterns I am about to share are the reason this works.

What I mean by ‘production-grade’. 15 best-practice skills.
When I say production-grade, I do not mean just “goes live and works”. I mean specific rules, enforced automatically by my skill files.
I have 15 best-practice skills related to building software. A few examples of the rules each one enforces:
- Coding (best-practice-code): No magic numbers. DRY. Single responsibility. Minimal coupling. Pure functions. Over 20 more rules. These are the rules that make AI-generated code survive past the demo.
- Database (best-practice-db): Normalize. No god tables. No autoincrement IDs because they do not scale. Store facts, not derivatives. Compliance RESTRICT, user data CASCADE. Again, over 20 more rules.
- UX/UI (best-practice-ux): DRY and no magic numbers applied to design tokens. Visible loading states. Never fail silently. 44px touch targets. Confirm destructive actions; optimistic UI for reversible ones. Again, over 20 more rules.
Every one of these rules fires automatically in my planning, implementation, and review loops. When I hand the AI a PRD or a feature spec, these rules always need to be applied. That is what production-grade means.

Clean code matters MORE in the AI era, not less
I get this objection every time: “Now that AI writes and reads code, does clean code still matter?” Answer: it matters more.
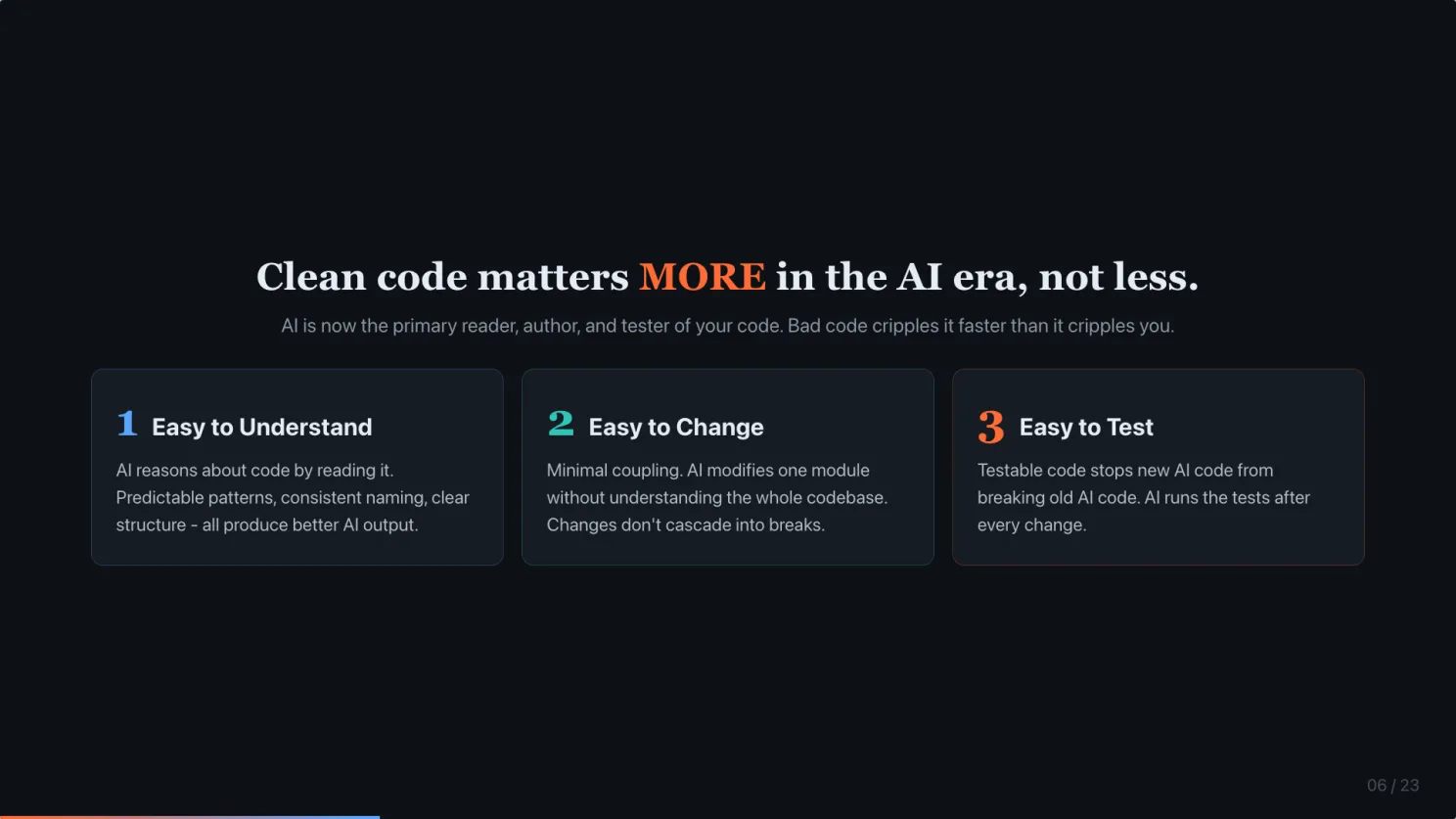
AI is the new reader, author, and tester of your code. Bad code cripples AI faster than it cripples humans. Three reasons.
Easy to understand. AI reasons by reading. Predictable patterns, consistent naming, clear structure. All produce better AI output.
Easy to change. Minimal coupling means AI can modify one thing without needing to grok the whole codebase. Changes do not cascade. It means better token efficiency.
Easy to test. This is the one most people do not think about. Testable code stops new AI code from silently breaking old AI code. The tests become the safety harness when the author is no longer a human.
So yes, clean code still matters. In fact, it is now a prerequisite for the AI workflow to even function.
Cursor shipped a feature in one shot, because my codebase was clean
Here is the moment that convinced me agentic coding was real.
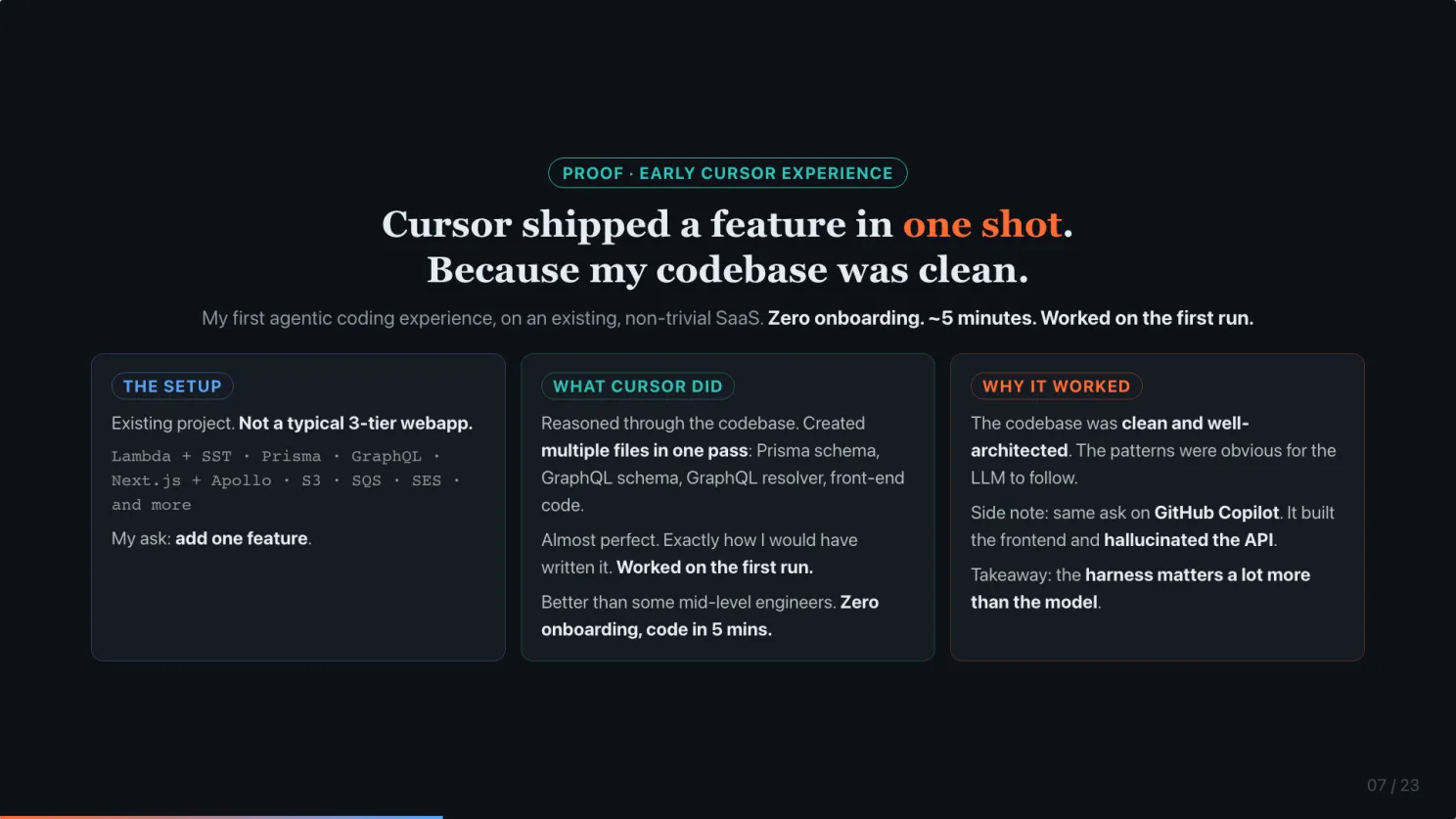
My first agentic coding experience. I pointed Cursor at an existing project of mine. Not a trivial 3-tier web app. The stack: Lambda on SST, Prisma, GraphQL, Next.js with Apollo Client, S3, SQS, SES, and more.
I asked it to add one feature. Cursor reasoned through the codebase, then created multiple files in one pass: Prisma schema, GraphQL schema, a new resolver, and the front-end code. I looked at the output. Almost perfect. Exactly how I would have written it. Worked on the first run. Zero onboarding. 5 minutes to code.
That was better than some mid-level engineers I have worked with.
Back then we still didn’t have a very strong model like Opus. So why did it work? In hindsight, because the codebase was clean and well-architected. The patterns were obvious. The LLM just followed them.
Side note. I tried the same ask on GitHub Copilot. It wrote the frontend, and hallucinated an API that did not exist. Same model. Different harness.
Two takeaways to hold onto. Clean code is the prerequisite. And the harness matters a lot more than the model. Both show up again later.
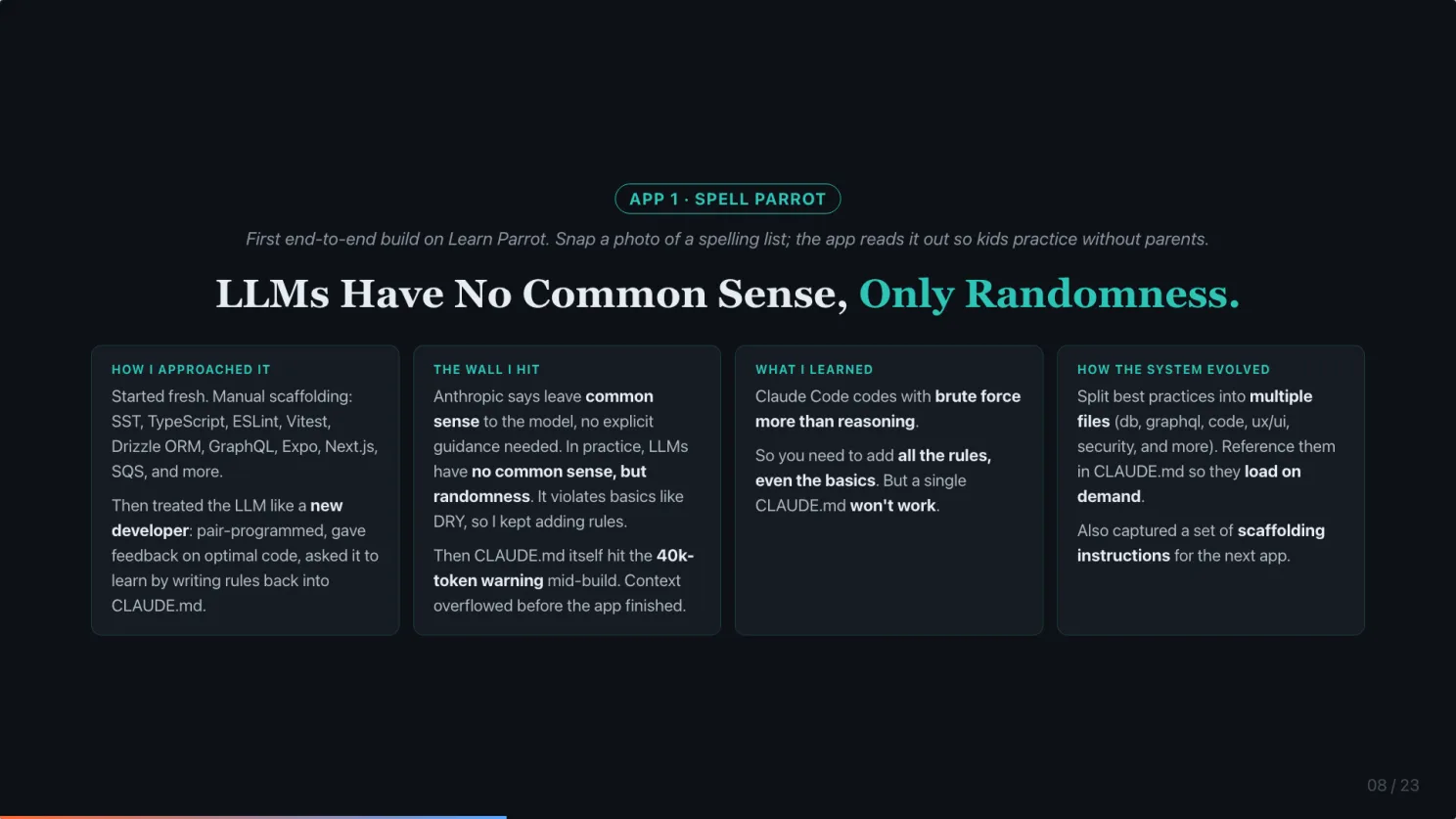
App 1, Spell Parrot. LLMs have no common sense, only randomness.
Then I embarked on a journey to create 3 learning apps for my kids. Let’s start with App 1.
Spell Parrot. First end-to-end build. Snap a photo of a spelling list and the app reads it out so kids can practice without their parents. It includes 2 mobile apps (Android and iOS), a GraphQL backend, and a marketing website. I built it to be scalable from Day 1. Check out Learn Parrot for what it does.
I knew LLMs are not good coders out of the box, so I treated Claude Code like a new developer. Pair-programmed, gave feedback on optimal code, asked it to learn by writing rules back into CLAUDE.md.
Here is what happened. Anthropic tells you to leave common sense to the model, no explicit guidance needed. In practice, LLMs have no common sense, only randomness. Claude Code kept violating basics like DRY, so I kept adding rules. Then CLAUDE.md itself hit the 40,000-token warning mid-build. Context overflowed before the app finished.
Main lesson from App 1: LLMs have no common sense, only randomness. You need to add all the rules, even the basics. But a single CLAUDE.md will not hold them.
The fix: split best practices into multiple files (db, graphql, code, UX/UI, security, and more), and reference them in CLAUDE.md so they load on demand.
App 2, AI Parrot. LLMs work for common CRUD, not complex logic.
AI Parrot is a ChatGPT for kids that won’t give direct answers. It asks guiding questions so kids think and figure out the answer themselves. Same Learn Parrot stack as Spell Parrot: 2 mobile apps (Android and iOS), a GraphQL backend, and a marketing website.
With on-demand loading and Spell Parrot as a reference codebase, magic happened. Half a day on the PRD, a few hours of coding, one day of tuning, shipped. A dream come true for an entrepreneur. I thought I could ship one idea per day.
Then I added subscription. I thought it was a common feature Claude Code could handle. I was wrong.
10 days lost to fixing subscription that supports 3 providers (Stripe, Apple, Google). Re-architected the webhook implementation 3 times. Race conditions and business logic bugs everywhere.
Lesson: Claude Code is good at common CRUD (schemas, basic UI, well-trodden patterns it has seen a million times). It fails on complex logic that needs engineering judgment: edge cases, concurrency, idempotency, multi-provider state. You still need a senior software engineer for the hard parts.
I added a dedicated best-practice-webhook.md to capture the subscription lessons, and more rules to the existing best-practice files for the edge cases Claude Code kept missing.

App 3, Grammar Parrot. Faster than a human. Less reliable than a senior engineer.
Grammar Parrot teaches grammar lessons across 282 topics in 14 categories on Learn Parrot. Same on-demand architecture as App 2. This is where the limitation of Claude Code surfaced.
I gave it the same setup. PRD, AI Parrot as a reference codebase, plus setup instructions and best practices. Asked it to implement everything, including subscription. Claude Code ran for a few hours. Told me it was all done.
Two things broke.
One. Lots of features were missing. A senior engineer on the same brief would have hit 90%. I spent 2 days working with Claude Code to test and fix them. AI codes faster than a human, but not as reliably as a senior engineer.
Two. I asked the main agent to write lesson content for 18 grammar topics in one run. It came up with a plan. It ran them one by one. Then it told me all 18 were done. I checked. It had written 4. The other 14 were stubbed as “Pending…”.
Later, I learned this is due to context anxiety. As the context fills up, the agent rushes to finish, takes shortcuts, and reports completion prematurely. It is not lying. It is degrading under load.
I also noticed instruction-following itself got worse late into each task. It started ignoring some best-practice rules. Counterintuitively, more rules made it worse. Context bloat is the cause.
I ended up feeding the same best practices 5 to 10 times to ask it to review the code and fix them. In hindsight, I was asking the AI to do reflection manually.
The skills-based system you are about to see was born from these two failures. Mine arrived as the response to getting burned.

But… can we make LLMs work harder?
After 3 apps and some disappointment, I asked one rhetorical question.
Can we make LLMs work harder?
The next 5 sections are the answer.

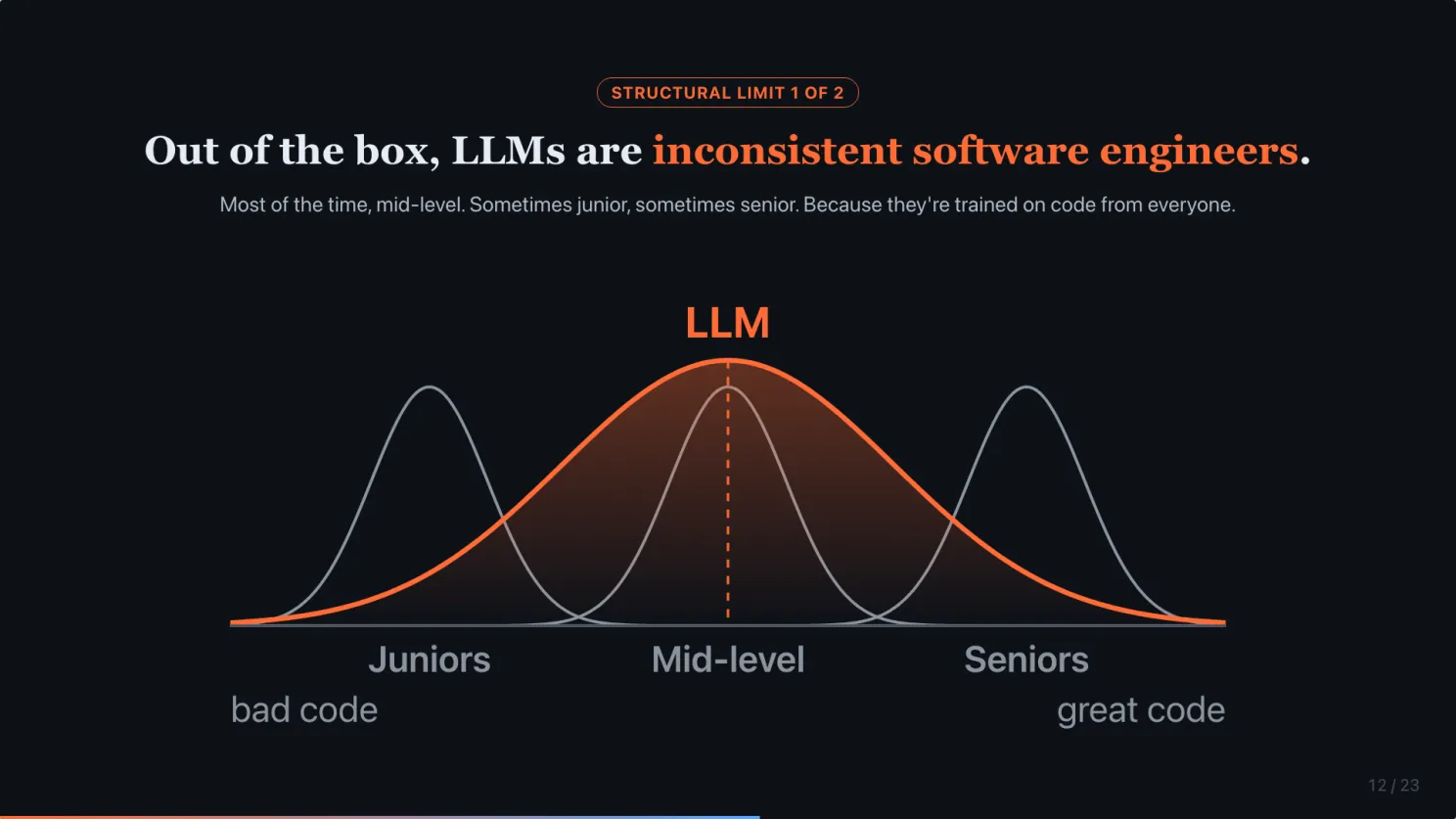
Out of the box, LLMs are inconsistent software engineers
Those 3 apps did not fail randomly. Here is the first of two structural limitations that explain why they failed.
Out of the box, LLMs are an averaging machine. They are inconsistent software engineers. Most of the time, they produce mid-level output. Sometimes junior. Sometimes senior. Why? Because they are trained on code from everyone. Juniors, mid-level, and seniors.
Picture this as a bell curve. Each human engineer has a tight, narrow distribution centered on their skill level. Juniors consistently produce bad code, mid-level engineers consistently produce average code, seniors consistently produce good code. The LLM has a wide, fat distribution centered on the middle, overlapping all three tiers. Same session, same prompt, you could get any of these.
This is the failure mode you watched across all 3 apps.
Pattern 1: Generator + Evaluator. Each subagent in fresh context.
Pattern 1. The reflection pattern. This answers structural problem 1: inconsistent output.
Two subagents, two fresh contexts. Both subagents load the same best-practice file for the scope. One file, two subagents. Generator follows it to produce output files, one or many depending on the task. Evaluator reviews those files against the same checklist and writes review-1.md. Any rule fails, the loop runs again. review-2.md, review-3.md, and so on. The loop exits only when every rule passes.
Three rules make this pattern work.
One. The orchestrator (your main thread, itself a skill) owns the loop. The generator does not decide to stop. The evaluator does not decide to continue. A skill outside the loop owns the control flow.
Two. Each subagent starts with fresh context. The evaluator has never seen the generator’s internal reasoning. That is the point. The same degraded context that produced the bug cannot reliably catch it.
Three. Every handoff is on disk. Output files from the generator. review-[n].md from the evaluator, one per loop. Nothing flows inline.
A note on planning. You might expect a separate planner subagent here. In practice, planning is itself a Generator + Evaluator loop. One pattern nests inside the other. Keep the pattern minimal.
I wrote a detailed post about this pattern at: https://www.linkedin.com/posts/boonkgim_ai-productivity-artificialintelligence-activity-7448541754607280128-rB3p

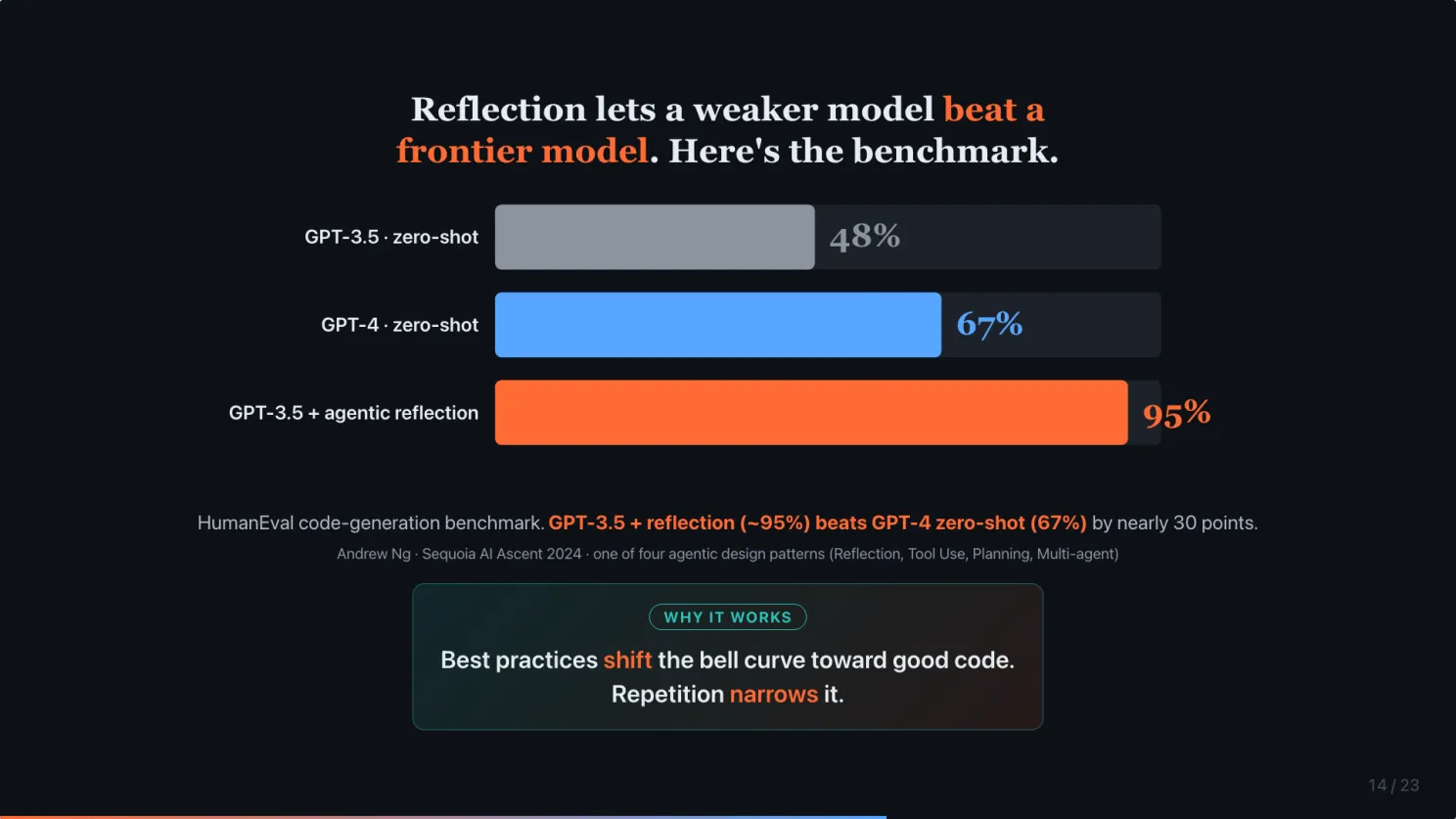
Reflection lets a weaker model beat a frontier model
This chart is from Andrew Ng’s Sequoia AI Ascent talk in 2024.
HumanEval is the standard code generation benchmark. GPT-3.5 zero-shot, 48%. GPT-4 zero-shot, 67%. That is the frontier-model jump everyone was excited about.
But GPT-3.5 with an agentic reflection workflow scores up to 95%.
Read it again. A weaker model with reflection beats a stronger model without it. By nearly 30 points.
Why does this work? Think back to the bell curve. Best practices shift the curve toward good code. Repetition narrows it. Shift the mean, shrink the variance. That is how we get senior-level output consistently.
This is the harness-vs-model thesis with a number behind it.
Instruction-following degrades from ~40% of the context window
Second structural limitation. This one produced both of the App 3 failures.
Instruction-following starts degrading around 40% of the context window. That measurement was taken on the original 200,000-token window. 40% of 200k is roughly 80,000 tokens.
Claude Code has since bumped the context to 1 million. But that does not fix it. The degradation is structural, not a function of how big you make the window. A 1M window just gives you more rope to hang yourself with.
Why structural? It is how the attention mechanism works. Every token attends to every other, and signal-to-noise drops as the sequence grows. This cannot be solved without new LLM architecture.
One wall, two symptoms. You saw both on App 3.
Symptom 1. Instruction-following decay. The agent quietly ignores your rules as the context fills.
Symptom 2. Context anxiety. The agent rushes, takes shortcuts, reports “done” when it is not.

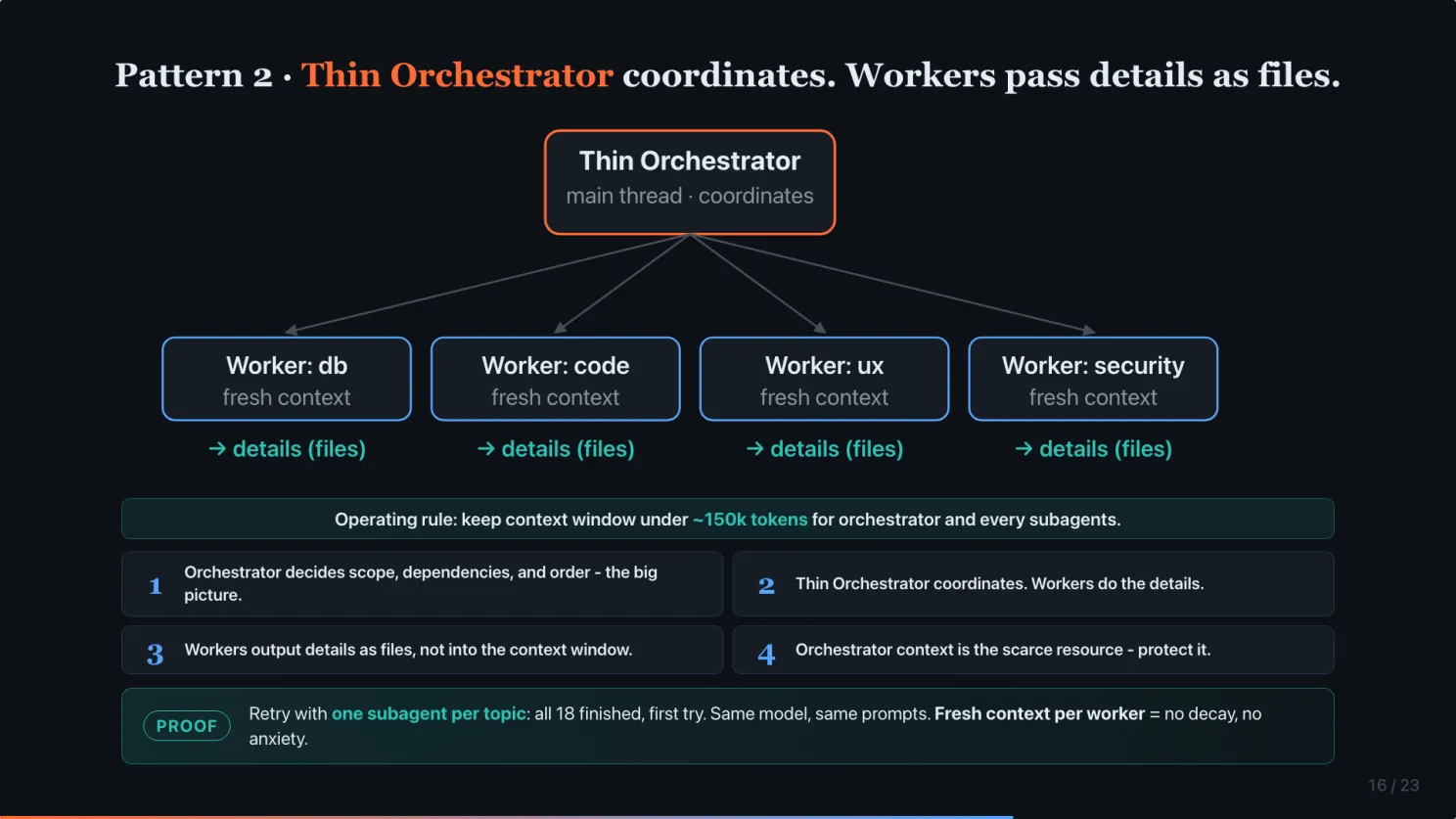
Pattern 2: Thin Orchestrator coordinates. Workers pass details as files.
Pattern 2. Thin Orchestrator + Specialized Workers, glued by file artifacts. This answers the 40% wall.
Emphasis on thin. The orchestrator is your main thread. The one you talk to. Its job is not to do the work. Its job is to coordinate. It owns the big picture and the order of things. It does not own the details.
The details live in the workers. Each worker is a subagent with its own fresh context, well below the wall. When a worker finishes, it does not return a thousand lines of inline text. It writes files and returns a path. The orchestrator reads the summary and passes paths, not content. Big picture up top, details on disk.
The operating rule falls straight out of it. Keep every task under roughly 150k tokens of context. Why 150k? I tried and it is very hard to complete some tasks under 100k.
Four rules.
One. Orchestrator decides scope, dependencies, and order. The big picture. For example, we can’t plan API before having DB schema.
Two. Thin Orchestrator coordinates. Workers do the details.
Three. Workers output details as files, not into the context window.
Four. Orchestrator context is the scarce resource. Protect it. If you let worker output flow through the orchestrator inline, you hit the wall in one or two steps.
Here is the proof. Remember App 3. 18 topics, 4 done. When I retried with one subagent per topic, all 18 finished, first try. Same model, same prompts. Different agentic pattern. Decay and anxiety both disappeared.
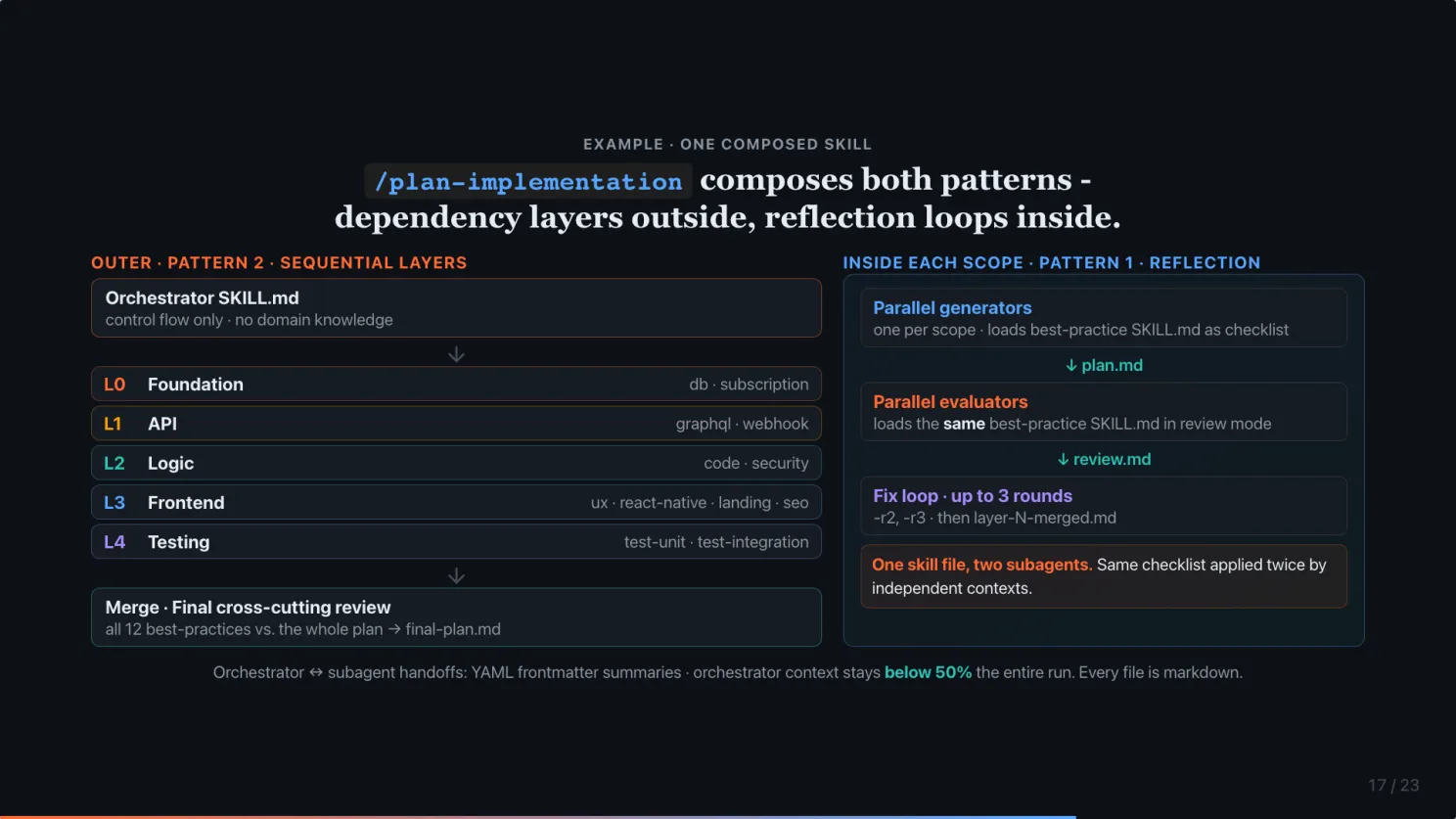
How both patterns compose inside /plan-implementation
Here is one of the actual skills that uses both patterns. This is what runs when I type /plan-implementation with a PRD. For context, this is only one of the skills I have. For software development, I have a set of skills like /prd, /system-architect, /ux-ui-system, /marketing-brief, /plan-implementation, /implement-plan, and more. All of them use both patterns.
The orchestrator SKILL.md holds no domain knowledge. Just control flow. It detects which best-practice scopes apply (12 of them, from database to GraphQL to security to UX), and then runs 5 dependency layers in sequence. Foundation. API. Logic. Frontend. Testing. All 15 best-practice SKILL.md files live separately. Subagents load them on demand.
Inside each scope, the reflection loop runs. For every in-scope best-practice, a generator spawns loaded with that scope’s best-practice SKILL.md as a checklist. Writes a plan file. Then an evaluator spawns loaded with the same best-practice file, now in review mode. Writes a review. If any review fails, it loops. Up to 3 rounds. Then merges the layer.
One skill file, two subagents, fresh context each time. That is what makes reflection honest. It is not the same subagent grading itself. It is the same checklist applied twice by independent subagents.
After all 5 layers pass, a merge subagent consolidates them. Then a final cross-cutting review loop runs every best-practice again, against the entire plan, because cross-layer violations only show up when the whole thing is assembled.
Pattern 2 on the outside. Sequential layers, file artifacts between them. Pattern 1 on the inside. Every handoff is a YAML frontmatter summary under 50 lines. That is how the orchestrator’s context stays below 50% the entire run.
These patterns reduce to four things to master
These two patterns reduce to 4 things you actually need to master. True for Claude Code. True for any agentic tool.
One. How to split a task into subagents, so no single run bloats.
Two. How to load the right context into each subagent, using skills.
Three. How to orchestrate those subagents from your main agent, without the main agent doing the work.
Four. How to pass context between agents as file artifacts, not inline.
Learn these 4. The rest is details.

Four rules. Break any one and the whole thing collapses.
If you remember nothing else, remember these 4.
One. Every skill file ≤ 40k tokens. Anything larger pre-loads context collapse before the agent starts working.
Two. Every task runs under ~100k tokens of context. Degradation starts at ~40% of the window, measured on the original 200k. In practice, it is hard to stay under 100k. The 1M context window does not help. It just gives you more rope.
Three. Every subagent starts with fresh context. The minute you share context between generator and evaluator, your evaluator becomes a confirmation-bias machine. The context that generates a bug cannot reliably catch it.
Four. Every handoff is a file artifact, never inline. Protect your orchestrator’s context like it is your last credit card. Because in this architecture, it is.
Break any one and the output quality degrades.

These patterns can be applied to any skill beyond coding. But… don’t start with them.
One piece of advice before I close.
These patterns are not just for coding. Any skill where quality matters (research, writing, analysis) composes the same way. For example, I run them on my /linkedin-post skill, my /presentation skill as well.
But… don’t start with them. Always start simple.
Stage 1. One skill file. Write your task as a single skill. Load it. Run it. If it works, it works.
Stage 2. If the quality is not consistent, then add the Generator + Evaluator reflection loop.
Stage 3. If context starts bloating, if you are hitting the 40% wall, then split into specialized subagents.
Agile applies to workflow engineering too. Pay the complexity tax only when a symptom shows up. These patterns burn a lot more tokens. That is the tax you are paying.

We were promised autonomous AI agents. What we got is Workflow Engineering 2.0.
This is my honest take about AI.
We were promised autonomous AI agents.
What we got is Workflow Engineering 2.0.
Plumbing, not magic. Workflow described in markdown, as a skill. It takes the domain expert to describe the workflow.

Prompts as “code”. Workflow > model.
The ceiling on your AI output is set by your workflow, more than your model. Upgrade the workflow first.
Two patterns. Four rules. Four skills to master. One expert orchestrator. That is the whole stack.

If you are coding 1 app with Claude Code, you probably do not need any of this. Start with one skill file. If you are coding 5+ apps and watching the same instruction-following decay show up every time, the patterns above are what fixed it for me.
#ClaudeCode #AIAgents #WorkflowEngineering #SoftwareEngineering #AI
Enjoyed this? Subscribe for more.
Practical insights on AI, growth, and independent learning. No spam.
More in AI Agents

I am attending the Agentic AI Conference by Data Science Dojo on May 27 and 28, 2025.
The conference speakers include thought leaders in industry who will talk about all aspects of building agentic AI applications - covering everything from cu...
I will be speaking about RIP CMS: How AI agents like OpenClaw could transform the way we create and...
See you guys there if you manage to get a ticket.

Two Choices for Handling Tech Debt in Vibe Coding
· Go full vibe: ignore tech debt, and when things inevitably break, spend a week fixing it.

Can DeepSeek R1 Run on a Normal Laptop for Free?
TL;DR

冬至快乐!Happy Winter Solstice Festival!
I’m curious to see how well Meta AI can create images of Chinese cultural festivals.
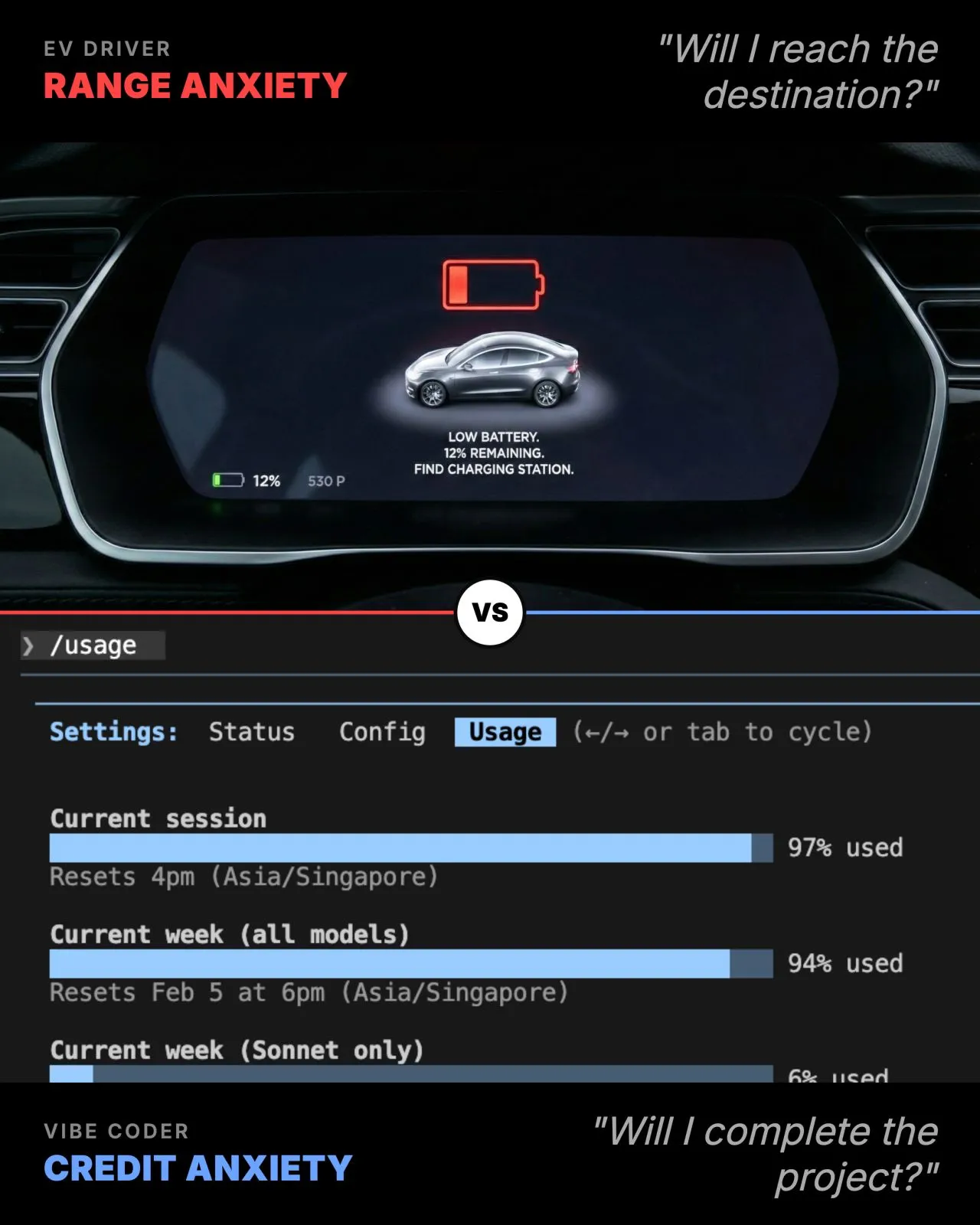
Range vs Credit Anxiety. Anyone? 🤪
If you have read my previous posts, I have shared how Claude Code performance tanks once your code and best practices hit a certain size due to context bloat...
I am attending the Agentic AI Conference by Data Science Dojo on May 27 and 28, 2025.
The conference speakers include thought leaders in industry who will talk about all aspects of building agentic AI applications - covering everything from cu...
Two Choices for Handling Tech Debt in Vibe Coding
· Go full vibe: ignore tech debt, and when things inevitably break, spend a week fixing it.
Range vs Credit Anxiety. Anyone? 🤪
If you have read my previous posts, I have shared how Claude Code performance tanks once your code and best practices hit a certain size due to context bloat...
I will be speaking about RIP CMS: How AI agents like OpenClaw could transform the way we create and...
See you guys there if you manage to get a ticket.
Can DeepSeek R1 Run on a Normal Laptop for Free?
TL;DR
冬至快乐!Happy Winter Solstice Festival!
I’m curious to see how well Meta AI can create images of Chinese cultural festivals.